在人工智能领域,英伟达作为行业领军者,推出了两种主要的GPU版本供AI服务器选择——NVLink版(实为SXM版)与PCIe版。
继续阅读
Google AI TPU
在人工智能领域,英伟达作为行业领军者,推出了两种主要的GPU版本供AI服务器选择——NVLink版(实为SXM版)与PCIe版。
继续阅读
CXL(Computer Express Link)是英特尔内部开发的专有链接标准,最初名为 IAL(Intel Accelerator Link),但后来更名为并向公众发布。
继续阅读
固态硬盘(SSD)已经成为数据存储的重要部分,其高速性能和稳定性让它广泛应用于各类计算设备中。SSD 固态硬盘的接口类型是决定其性能的关键因素之一。
继续阅读
本文将深入探讨CXL技术,从其起源、特点,到应用领域和与其他技术的比较,全面了解CXL对现代数据中心生态系统的重要性。
继续阅读
2020年,全球企业级SSD市场规模为178.5亿美元,预计到2030年将达到468.9亿美元,自2021年至2030年的年复合增长率为10.2%。
继续阅读
本文将对这些影响PCIe链路性能的因素做一个简单盘点,看看它们是如何影响PCIe实际性能发挥的。
继续阅读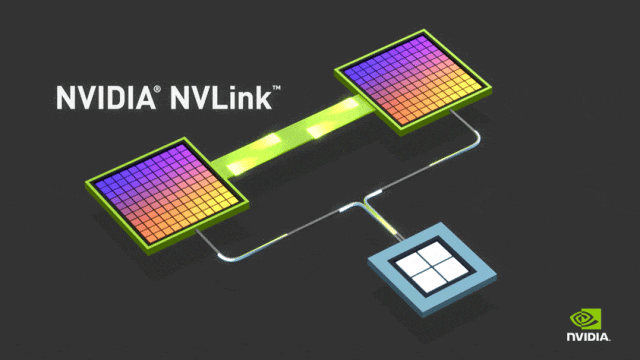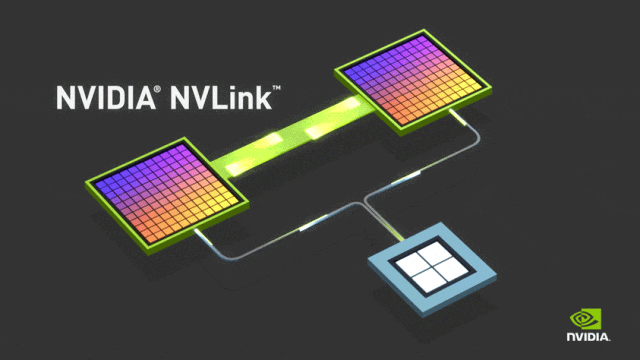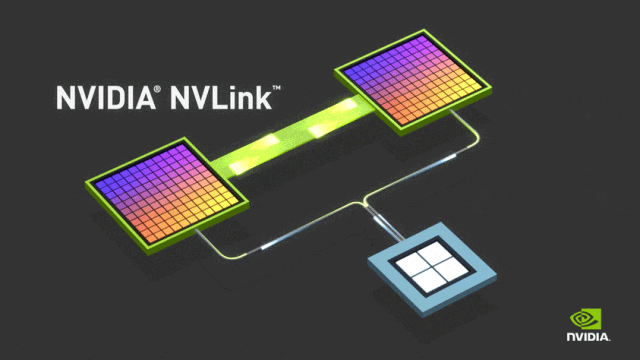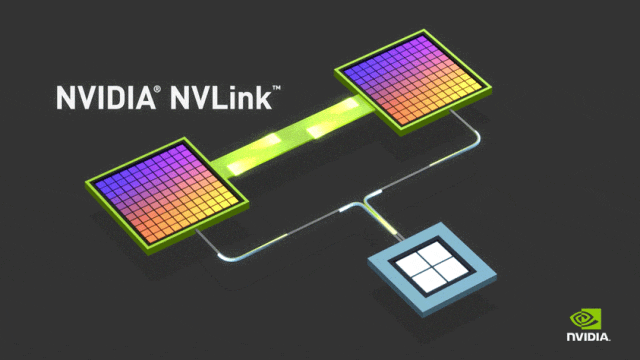
随着人工智能和图形处理需求的不断增长,多 GPU 并行计算已成为一种趋势。
继续阅读
Habana® Gaudi®2 处理器是一款高性能、完全可编程的AI处理器,从计算架构、内存和扩展能力三个维度进行技术创新,以领先的性价比优势加速深度学习训练与推理。
继续阅读
应该预先以整体性的方式来解决存储扩展问题。这包括容量、性能、网络硬件和数据传输协议。其中的关键点是确保充足的GPU资源,否则,训练和推理工作可能会失败。
继续阅读
NVLink的目标是突破PCIe接口的带宽瓶颈,提高GPU之间交换数据的效率。2016年发布的P100搭载了第一代NVLink,提供160GB/s的带宽,相当于当时PCIe 3.0 x16带宽的5倍。
继续阅读