GPU在扩展AI方案方面有许多优势,从更快的模型训练到GPU加速的欺诈检测。在规划AI模型和部署应用程序时,必须考虑到可扩展性挑战,尤其是在性能和存储方面。
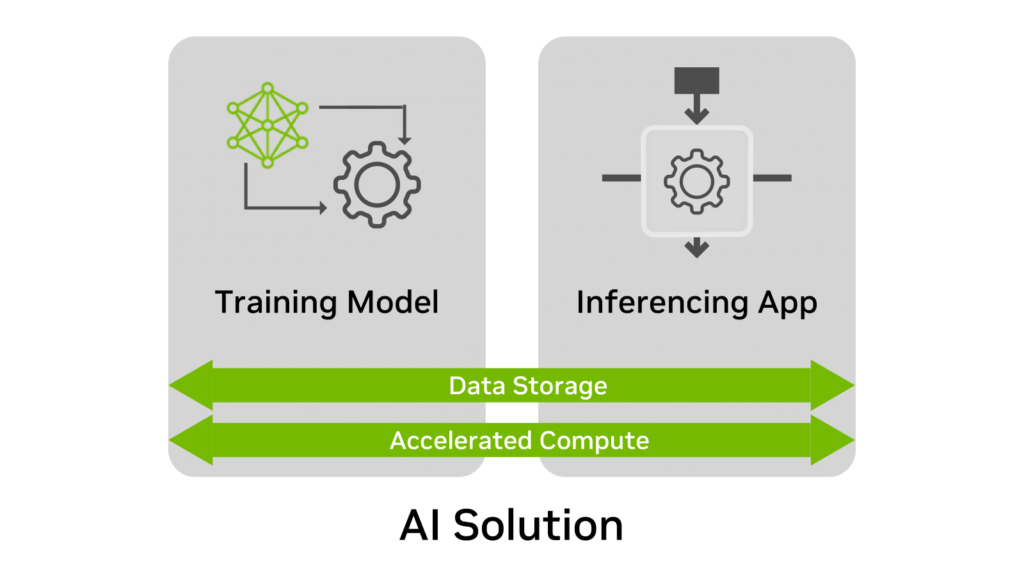
无论用途如何,AI解决方案通常有四个要素:
- 训练模型
- 推理应用
- 数据存储
- 加速计算
在这些要素中,数据存储在规划过程中通常是最容易被忽视的。
为什么呢?因为在创建和部署AI解决方案时,并不总是考虑到数据存储需求随着时间的推移而发生变化。大多数AI部署的要求通常可以通过POC或测试环境快速确认。
然而,挑战在于POC往往只针对某个特定时间点。训练或推理部署可能会持续数月或数年。由于许多公司迅速扩展其AI项目的范围,基础设施也必须扩展,以适应不断增长的模型和数据集。
本文中将解释如何提前规划和扩展用于训练和推理的数据存储。
AI的数据存储层次结构
首先,了解AI的数据存储层次结构,包括GPU内存、数据存储网络和存储设备(图2)。
一般来说,存储层次结构中位置越高,存储性能(尤其是延迟)就越快。在本讨论中,存储被定义为在电源开启或关闭时存储数据的任何设备,包括内存。
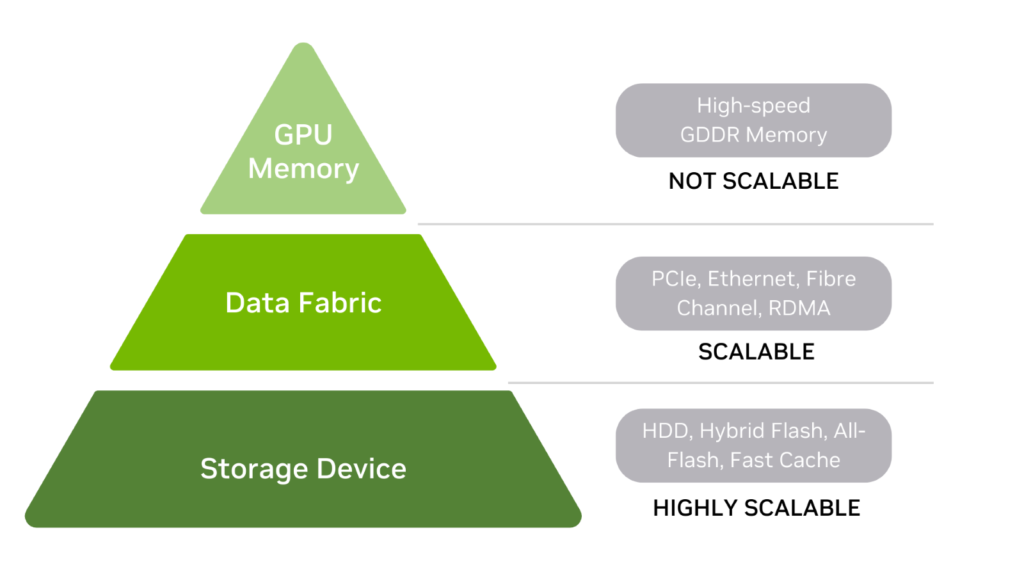
存储设备
HDD和SSD位于存储层次结构的底部。还有一些混合介质存储是两者的组合。HDD可以在前端带有快速缓存层,而全闪存存储可能使用SCM来提高读取性能。
快速存储在将大型数据集加载到GPU内存中的情况下非常有用。当需要训练一个已经不适合存储设备的模型时,很容易扩展存储容量。还可能需要存储多个数据集 —— 这是具有可扩展存储的另一个原因。
数据网络
在整体架构中间,数据网络用于连接存储设备和GPU内存。包括:
- PCIe总线
- 网卡
- DPU
- 存储和GPU内存之间数据路径中的其它任何板卡
为了保持简单,可以将数据网络简单地视为存储设备和GPU内存之间的传输数据层。
GPU内存
在存储层次结构的最顶层是GPU内存(通常称为vRAM)。由于GPU内存速度快且直接连接到GPU,当整个模型存储在内存中时,训练数据集可以快速处理。CPU内存也位于层次结构的最顶层,就在GPU内存的下方。
另外,模型数据可以分批次发送到GPU内存。较大的GPU内存可以减少批次数,从而加快训练时间。如果GPU在处理模型或数据集的任何部分时需要遍历数据网络,将活动交换到数据盘会大大降低训练性能。
需要记住的是,虽然存储设备和数据网络可以扩展,但GPU内存是固定的。这意味着GPU内存已配置给GPU,内存大小无法升级以支持更大的训练模型和数据集。
如果GPU制造商支持,可以通过NVIDIA NVLink等方式增加GPU内存。然而,并非所有系统都能容纳第二个GPU和额外内存的可能性。
最终,部署计划应包括GPU内存远远超过当前需求。未来解决内存不足问题可能会非常昂贵。
在推理中扩展存储时需要考虑的因素
推理是AI解决方案的价值所在。因此,需要有效的存储。
为了确保推理的存储是可扩展的,考虑以下因素:
纵向扩展和横向扩展
存储的可扩展性不仅仅是容量的问题,也包括性能。真正的横向扩展确保当容量和性能需求增加时,存储系统可以提供更多的容量和性能。
我们来看一个纵向扩展和横向扩展的现实世界例子。在旧金山的旅游区,有许多人力三轮车。单个骑手或驾驶员可以推动一个可容纳两个、四个或甚至六个乘客的人力三轮车。
当只有一个乘客时,骑手可以快速骑行,更快地到达目的地,并更快地寻找新的乘客。而当人力三轮车上载更多乘客时,加速度减慢,最高速度降低,一天的运载次数也减少。人力三轮车是纵向扩展的例子。
我们可以轻松增加运载量,但由于受限于单个骑手的动力,性能不会等比例增加。而在横向扩展的例子中,每增加一个乘客,就有一个额外的骑手为其推动。当动力和容量线性增长时,性能永远不会成为瓶颈。
对于推理而言,真正的横向扩展需要在容量和性能两方面同时扩展。推理服务器可以随着时间存储大量数据。存储的读写性能必须扩展,以避免推理结果的延迟。
此外,存储容量还必须扩展,因为语音、图像、客户配置文件和其它数据在推理应用执行时会被写入存储。还需要高效地存储重新训练的数据,用于反馈到模型中。
无缝升级
某些推理应用不能很好地容忍停机时间。例如,在线商店的欺诈检测应用何时关闭是最佳时机?当关闭网络商店推荐引擎来升级存储容量或性能时,将损失多少订单?
可以受到维护升级影响的推理应用有很多。例如:
- 用于客户服务的对话式AI应用。
- 24/7视频流智能洞察分析。
- 关键的图像识别应用。
除非推理可以容忍维护时间窗口,否则扩展容量和性能将成为一项挑战。在承诺特定存储部署之前,最好先考虑存储升级和可用性的方案。
实时性要求
以在线交易的欺诈检测为实时推理的例子。推理应用程序寻找异常行为和交易配置文件,揭示不可接受的风险。用户在等待交易批准的同时,需要在几分之一秒内做出数百个决策。低延迟存储和高性能数据网络连接对于实时交易至关重要,特别是当风险参数必须迅速从存储中检索时。
亚毫秒级存储性能是某些实时性应用的基本要求,这些应用受益于存储和GPU内存之间的高性能通道。NVIDIA利用RDMA协议加速从存储到vRAM的数据传输,通过名为NVIDIA GPUDirect Storage的功能实现。这可以缩短GPU实时检索存储数据(例如风险配置数据)所需的时间。检索到的配置和风险数据点后续可能会被重新分析,以提高准确性。
NVIDIA GPUDirect技术支持GPU内存和本地NVMe存储之间的DMA直接数据通道事务,或通过NVMe-oF与远程存储的通信。
纠正工作中的疏忽
在规划过程中通常会有改进的空间。在训练和推理过程中,一些常见的与存储相关的疏忽包括可扩展性、性能、可用性和成本。
在训练中,可以通过以下方法避免这些疏忽:
- 始终部署远远超过当前需求的GPU内存。
- 总是考虑未来模型和数据集的大小,因为GPU内存不可扩展。
在推理中,可以通过以下方法避免这些疏忽:
- 在预计性能和容量随时间增长时,选择横向扩展存储。
- 选择支持无缝升级的存储,特别是对于没有或几乎没有维护时间窗口的应用。
- 未来可能无法实现或不切实际支持实时推理应用的存储升级。在初次部署GPU、存储和数据网络之前做出这些决策。
本文要点
应该预先以整体性的方式来解决存储扩展问题。这包括容量、性能、网络硬件和数据传输协议。其中的关键点是确保充足的GPU资源,否则,训练和推理工作可能会失败。