DAOS是一种先进的分布式存储系统,它是专门为现代硬件重新设计的存储堆栈。
继续阅读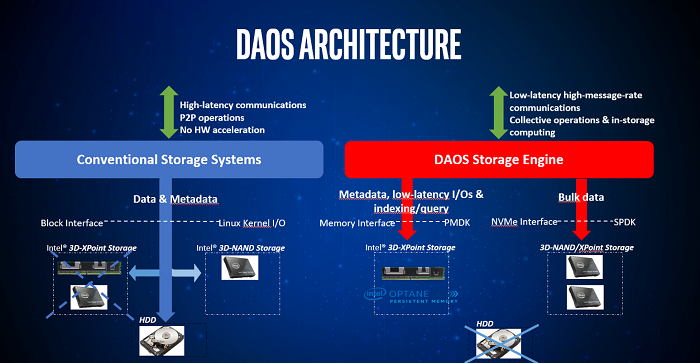
Google AI TPU
DAOS是一种先进的分布式存储系统,它是专门为现代硬件重新设计的存储堆栈。
继续阅读
基于HBM3E,H200带宽可达4.8TB/s(比H100的3.35TB/s提升43%),并且内存容量从80GB提升至141GB,这使得H200成为高性能计算(HPC)和人工智能等领域的理想选择。
继续阅读本文探讨了这两种工作负载类型和技术之间的差异和共性,概述了在多个层面实现整合的途径。并预测新兴的智能网络解决方案将加速这种整合的过程。
继续阅读
在单个GPU性能有限的情况下,将两个或多个GPU连接起来这种在当时看起来非常荒谬的想法竟然渐渐成为提升系统GPU性能的主流方法。
继续阅读
基于闪存的NVMe SSD具有低廉的价格并提供高吞吐量。将多个这些设备整合到单个服务器中,可以实现高达1000万IOPS。
继续阅读
橡树岭国家实验室(ORNL)将发布一份关于下一代高性能计算(HPC)系统,即计划于2027年交付的OLCF-6的需求建议书(RFP)。
继续阅读随着AI不断演进,成为一个具有统计和数学严密性的计算范式,显而易见的是,对于科学设施产生的数据,单一GPU解决方案已不再足以满足训练、验证和测试的需求。
继续阅读
HPC指的是在多台服务器上以高速并行方式执行复杂计算的能力。这些服务器的集合被称为集群,由数百甚至数千台计算服务器通过网络连接而成。
继续阅读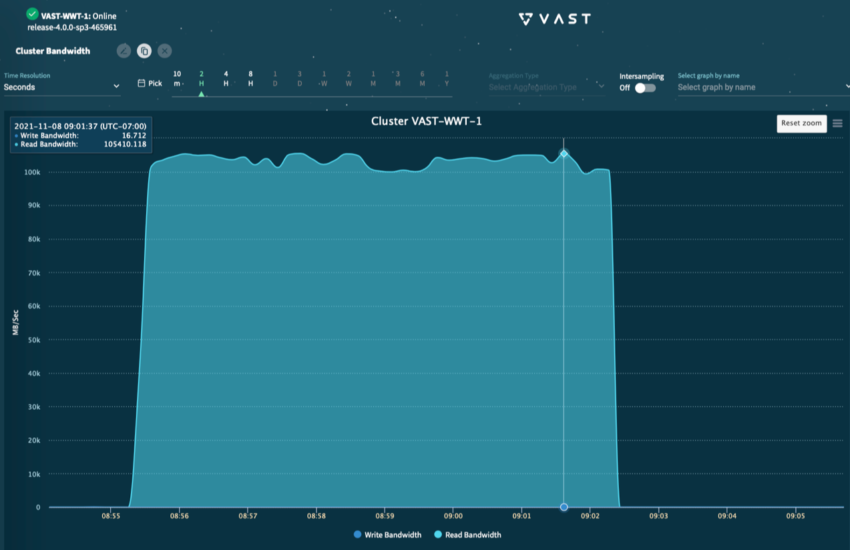
随着AI/ML解决方案在企业中崭露头角,我们的许多客户发现传统的存储系统和文件系统可能无法满足与新的AI/ML工作负载相关的新需求。
继续阅读
RDMA技术涵盖了四种实现方式:InfiniBand、RoCEv1、RoCEv2以及iWARP。在这其中,RoCEv1已经过时,iWARP并不常见。目前,业界普遍采用的网络解决方案主要集中在InfiniBand和RoCEv2两个选项之间。
继续阅读