
NVLink的目标是突破PCIe接口的带宽瓶颈,提高GPU之间交换数据的效率。2016年发布的P100搭载了第一代NVLink,提供160GB/s的带宽,相当于当时PCIe 3.0 x16带宽的5倍。V100搭载的NVLink2将带宽提升到了300 GB/s,接近PCIe 4.0×16的5倍。A100搭载了NVLink3,带宽为600GB/S。
H100搭载的则是NVLink4。相对NVLink3,NVLink4不仅增加了链接数量,内涵也有比较重大的变化。NVLink3中,每个链接通道使用4个50Gb/s差分对,每通道单向25GB/s,双向50GB/s。A100使用12个NVLink3链接, 总共构成了600GB/s的带宽。NVLink4则改为每链接通道使用2个100Gb/s差分对,每通道双向带宽依旧为50GB/s,但线路数量减少了。在H100上可以提供18个NVLink4链接,总共900GB/s带宽。
NVIDIA的GPU大多提供了NVLink接口,其中PCIe版本可以通过NVLink Bridge互联,但规模有限。
更大规模的互联还是得通过主板/基板上的NVLink进行组织,与之对应的GPU有NVIDIA私有的规格SXM。SXM规格的NVIDIA GPU主要应用于数据中心场景,其基本形态为长方形,正面看不到金手指,属于一种mezzanine 卡,采用类似CPU插座的水平安装方式“扣”在主板上,通常是4-GPU或8-GPU一组。其中4-GPU的系统可以不通过NVSwitch 即可彼此直连,而8-GPU系统需要使用NVSwitch。


此图完整展现了主要结构、安装形式和散热。其中右侧的两块A100 SXM没有安装散热器。右上角未覆盖散热器的细长方形芯片即为NVSwitch。
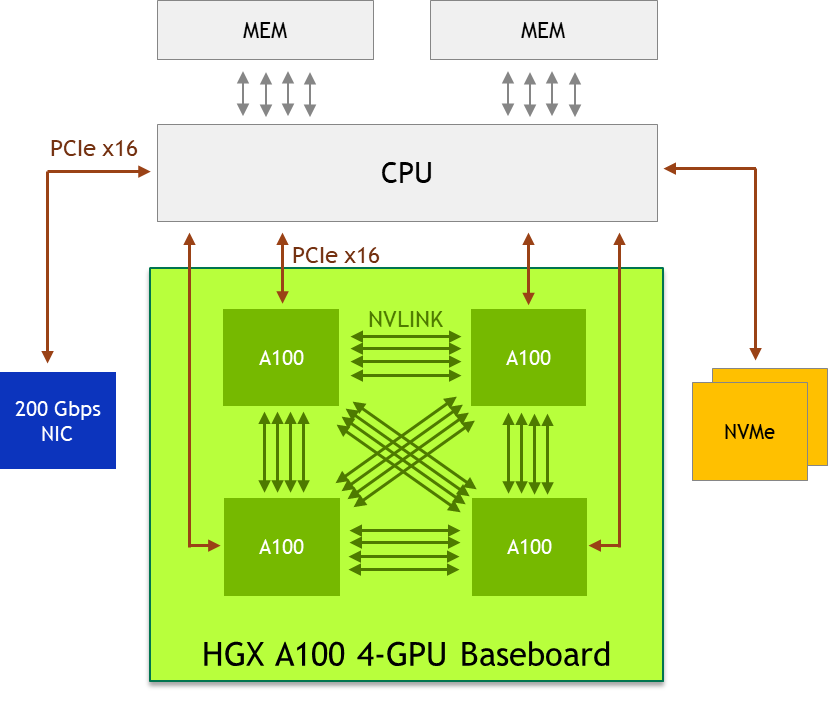
每个A100的12条NVLink被均分为3组,分别与其他3个A100直联。
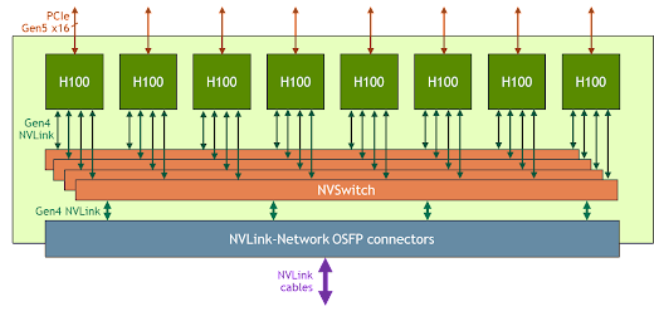
每个H100的18条NVLink被分为4组,分别与4个NVSwitch互联。
经过多代发展之后,NVLink日趋成熟,已经开始应用于GPU服务器之间的互连,进一步扩大GPU(及其显存的)集群规模。






