
Habana® Gaudi®2 处理器是一款高性能、完全可编程的AI处理器,从计算架构、内存和扩展能力三个维度进行技术创新,以领先的性价比优势加速深度学习训练与推理。同时,它具有高内存带宽/容量和基于标准以太网技术的纵向扩展能力,支持使用外接网卡通过PCIe接口实现横向扩展,可满足多节点集群需要,专为训练大语言模型构建,是大规模部署AI的更优解。使用SynapseAI® 软件套件,可以在Habana® Gaudi®2 平台上实现简单、高效的模型开发和迁移,助力AI应用特别是LLM等大模型的落地。
什么是SynapseAI® 软件套件
SynapseAI® 软件套件专为优化基于 Habana AI 处理器的高性能深度学习 (DL) 训练而设计,能够将神经网络拓扑高效映射到 Gaudi® 硬件系列上。SynapseAI® 软件套件包括 Habana 的图编译器和运行时、TPC 算子库、固件和驱动程序以及开发工具,例如用于开发自定义核心的 TPC 编程工具套件和 SynapseAI Profiler。SynapseAI 与 TensorFlow 和 PyTorch 等主流框架集成,并已面向 Habana 的 Gaudi® 和 Gaudi®2 AI 处理器进行了性能优化。图 1 为 SynapseAI® 软件套件的构成示意图。
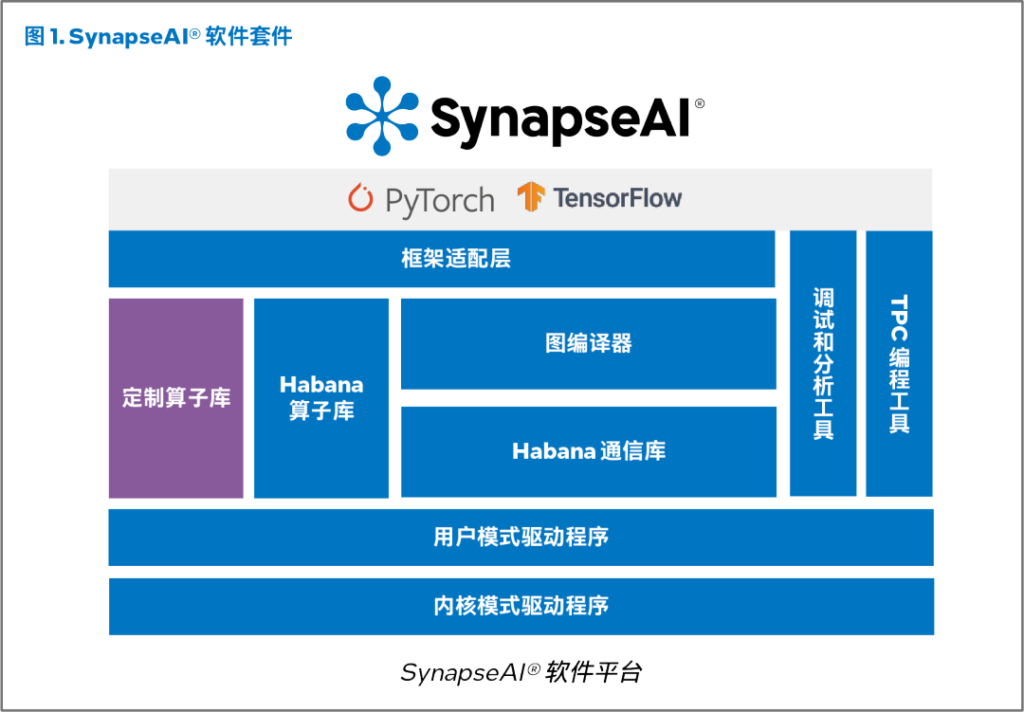
图编译器和运行时
SynapseAI 图编译器会生成经优化的二进制代码,在 Gaudi® 上实现给定的模型拓扑。它执行算子融合、数据布局管理、并行化、流水线管理、内存管理以及图级优化。这一图编译器使用的是丰富的 TPC 算子库,库中包含各种经过性能优化的算子 (operator) [例如,元素类 (elementwise)、非线性、非 GEMM 算子]。鉴于 Gaudi® 硬件的异构性质(矩阵数学引擎、TPC 和 DMA),SynapseAI 图编译器还以并行和流水线方式执行框架图,实现硬件的有效利用。SynapseAI 采用流式架构来管理异步任务的并发执行,可支持 Gaudi® 独特的计算与网络组合,并为框架提供多流式架构接口。不同类型的流(计算、网络和 DMA)彼此间会以高性能和低运行时开销实现同步。
Habana 通信库
Habana 通信库利用 Gaudi® 的高性能 RDMA 通信功能,既可以在单个节点内的 Gaudi® 处理器之间实现高效的纵向扩展通信,也可以跨节点实现横向扩展通信,支持分布式训练。

它具有 MPI 的外观和体验,支持点对点操作(如 Write、Send)和集合操作(如 AllReduce、AlltoAll)。值得一提的是,这些操作已面向 Gaudi® 进行了性能优化。Habana 集合通信库 (HCCL) 是 Habana 使用与 NCCL 兼容的 API 对标准集合通信例程的实现。
TPC编程
SynapseAI TPC SDK 包括基于 LLVM 的 TPC-C 编译器、模拟器和调试器。这些工具有助于开发自定义 TPC 内核。我们便是使用这一 SDK 构建了 Habana 提供的高性能内核。用户因此可以开发基于 Gaudi® 的定制化深度学习模型和算法,以便根据自己的特定需求进行创新和优化。
TPC 编程语言 TPC-C 是 C99 的衍生语言,它增加了语言数据类型,可以轻松利用处理器独有的 SIMD 功能。TPC-C 原生支持宽矢量数据类型(如 float64、uchar256 等),可以协助 SIMD 引擎的编程。它具有多个内置的深度学习指令,包括基于张量的内存访问、特殊函数加速和随机数生成,可支持多种数据类型。
深度学习框架集成
Habana SynapseAI 集成了数据科学家和 AI 开发人员常用的两个框架 PyTorch 和 TensorFlow。我们将简要概述 SynapseAI TensorFlow 集成,并说明 SynapseAI 如何在幕后完成大部分映射和优化工作,以便让客户仍能获得他们当前所习惯的相同体验。
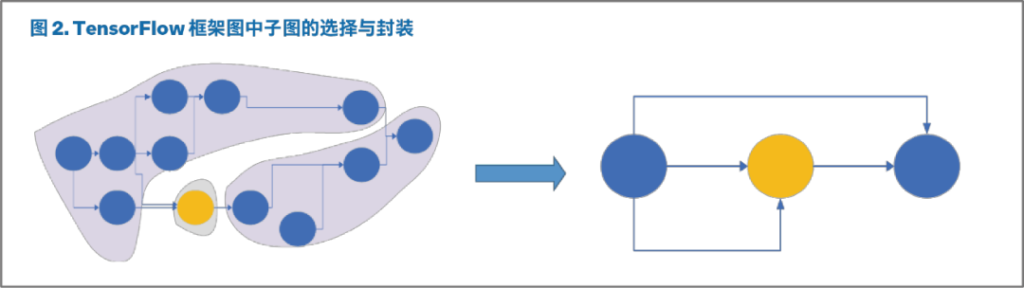
SynapseAI TensorFlow 桥接层从 TensorFlow 框架接收模型的计算图,并识别可以由 Gaudi® 加速的图的子集。这些子图被封装在 Gaudi® 上,并实现了执行优化。图 2 为在 TensorFlow 框架图上执行封装的示例。黄色节点在 Gaudi® 上不受支持,而蓝色节点可以在 Gaudi® 上执行。
有蓝色节点的子图被识别并封装。原始图经过修改后可使用子图对应的封装节点替代子图。
随后,框架运行时会执行修改后的图。每个节点都会创建并编译相应的 SynapseAI 图。为了优化性能,编译配置会被缓存,以供将来使用。完成内存分配后,该配置将进入队列排队,等待在 SynapseAI 流上执行。
SynapseAI 支持通过 Horovod 和 tf.distribute API 以及 HPUStrategy 进行 TensorFlow 分布式训练。您可通过 tf.keras.mixed_precision API 或使用 Habana 的自动混合精度转换功能实现混合精度执行。这些方法让您无需对现有 FP32 模型脚本进行大量修改,即可运行混合精度训练。更多详情,请见 docs.habana.ai 的 TensorFlow 部分。
SynapseAI PyTorch 桥接层将 PyTorch 框架和 SynapseAI 软件堆栈二者的接口连接起来,以在 Gaudi® 上训练基于 PyTorch 的深度学习模型。我们支持两种执行模式:(1) Eager 模式——按照标准 PyTorch Eager 模式脚本的定义,逐个算子地执行;(2) Lazy 模式——延迟执行由一系列算子组成的图。Lazy 模式提供类似于 Eager 模式的用户体验,同时可在 Gaudi® 上实现高性能。默认情况下,我们启用 Lazy 模式执行。SynapseAI 桥接层不是一次执行一个算子,而是在内部将算子累积在一个图中。仅当用户需要张量值时,才会以“Lazy”方式触发图中累积的算子的执行操作,这使 SynapseAI 桥接层能够构建一个图,让 SynapseAI 图编译器有机会针对设备进行算子优化。
您可通过 Habana 混合精度 (HMP) 包实现混合精度执行。HMP 包会通过自动修改 Python 算子来添加适当的类型转换算子。如此一来,您无需对现有 FP32 模型脚本进行大幅修改,即可运行混合精度训练。SynapseAI PyTorch 桥接层支持使用 torch.distributed 和 torch.nn.parallel.DistributedDataParallel API 进行分布式训练,实现数据并行和模型并行。而使用 HCCL 后端则可启用分布式通信。更多详情,请见 docs.habana.ai 的 PyTorch 部分。
此外,SynapseAI 还与 TensorBoard 集成,支持 TensorFlow 或 PyTorch 模型的调试和分析。对底层分析感兴趣的用户可以参阅 docs.habana.ai 网站上的 SynapseAI Profiler 用户指南。
系统管理和监控
SynapseAI® 软件套件提供监控和管理支持,这对于服务器开发人员和管理服务器部署的 IT 人员来说很有用。Habana Labs 管理库 (HLML) 是一个 C 语言编程接口,用于监控和管理 Habana AI 处理器内的各种状态。Habana 系统管理界面 (hl-smi) 是基于 HLML 的命令行工具,旨在帮助管理和监控 Habana AI 处理器。而 Habana Labs Qualification (hl_qual) 工具包则提供验证和鉴定服务器设计中 Gaudi® 硬件平台使用和集成情况所需的工具。
编排
Kubernetes 是一个编排系统,可以实现生产集群中容器运行流程的自动化。它消除了部署、扩展和管理容器化应用带来的基础设施复杂性。基于 Kubernetes 的容器编排通常用于部署 AI 工作负载,SynapseAI 则提供必要的组件,支持在 Kubernetes 集群中启用 Gaudi®。Habana 设备插件支持在容器集群中注册 Habana 设备,以满足计算工作负载的需要。通过在 Kubernetes 集群中部署合适的硬件和此插件,您将能够运行那些需要使用 Habana 设备的作业。Habana 使用来自 Kubeflow 的标准 MPI Operator,支持在 Kubernetes 集群中利用 Gaudi® 处理器运行 MPI 全归约式工作负载。这样一来,您便可以使用 Kubernetes 作业分配模型在 Gaudi® 上运行分布式训练。为了监控集群运行状况,SynapseAI 还支持面向 Kubernetes 的 Prometheus Metric Exporter。这是一个守护进程集,可以在容器集群中收集设备指标,满足计算工作负载的需要。SynapseAI 支持多种类型的 Kubernetes 编排,包括普通的开源 Kubernetes、Amazon EKS、RedHat OpenShift 和 VMware Tanzu。
Gaudi® 平台上的模型迁移
显然,从熟悉的深度学习平台和工作流程迁移到新的平台和工作流程并非易事。我们的目标是尽可能简化迁移工作,降低迁移的门槛。我们预计,大多数用户在对现有脚本进行少量更改后即可在 Gaudi® 上运行现有模型。Habana GitHub 将提供迁移指南和示例,帮助用户将现有模型移植到 Gaudi® 上运行。有关将模型迁移到 Gaudi® 的更多信息,请参阅 docs.habana.ai 上的迁移指南。
SynapseAI TensorFlow 和 PyTorch 用户指南概述了 SynapseAI 与各框架的集成、所支持的 API 和算子,以及如何实现混合精度训练和分布式训练,等等。迁移指南可以帮助用户更好地了解如何将现有模型移植到 Gaudi®,并提供了有助于完成模型迁移的实用技巧。
下面我们展示了移植不包含任何自定义核心的 TensorFlow Keras 模型所需的最小更改。
import tensorflow as tf
from TensorFlow.common.library_loader import load_habana_module
load_habana_module()
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(10),
])
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
model.compile(optimizer=optimizer, loss=loss, metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5, batch_size=128)
这些为支持在 Habana® Gaudi® 设备上进行训练所作的最小更改以粗体突出显示。您只需要导入 load_habana_module 包,然后调用 load_habana_module() 函数即可在 Gaudi® 上进行训练。通过以上更改,Gaudi® 设备(在该框架中称为 HPU)现已在 TensorFlow 中注册,其执行优先级高于 CPU。也就是说,当某个算子同时适用于 CPU 和 HPU 时,该算子将会分配给 HPU;当该算子不适用于 Gaudi® 时,便在 CPU 上运行。类似的方法也适用于迁移 PyTorch 模型。
满足开发者需求,与AI软件生态合作
Habana 的目标是满足开发人员的需求。我们一直在与 AI 软件生态系统合作伙伴开展合作,利用 Habana AI 处理器实现无缝用户体验。下面简要介绍Habana与多个主流AI生态的合作与集成:
Hugging Face 上的 Transformer 模型与 Gaudi®
在深度学习的支持下,Transformer 模型可以为自然语言处理、计算机视觉、语音等多种机器学习任务提供出色的性能。而Hugging Face 是开源软件历史上增长最快的项目之一,也是机器学习社区青睐之地。Habana 的 SynapseAI® 软件套件与 Hugging Face Optimum 开源库集成后,数据科学家和机器学习工程师只需几行代码即可在 Habana AI 处理器上加速其 Transformer 训练作业,从而提高生产力,降低训练成本。
这里有两大类需要了解:(1) GaudiTrainer 类,负责编译(Lazy 或 Eager 模式)和分配模型到 HPU 上运行,以及执行训练和评估;(2) GaudiConfig 类,负责配置 Habana 混合精度并决定是否应当使用优化的算子和优化器。GaudiTrainer 与 Transformers Trainer 非常相似,大部分情况下,只需将 Trainer 类换为 GaudiTrainer 类,即可将使用 Trainer 的脚本改编成能在 Gaudi® 上使用的脚本。HuggingFace Habana 网页上提供了几个常见的参考模型,包括 BERT Base、BERT Large、RoBERTa Base、RoBERTa Large、DistilBERT Base、ALBERT Large 和 ALBERT XXLarge。
from optimum.habana import GaudiConfig, GaudiTrainer, GaudiTrainingArguments
# A lot of the same code as the original script here
...
# Loading the GaudiConfig needed by the GaudiTrainer to fine-tune the model on HPUs
gaudi_config = GaudiConfig.from_pretrained(
training_args.gaudi_config_name,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
use_auth_token=True if model_args.use_auth_token else None,
)
# Initialize our Trainer
trainer = GaudiTrainer(
model=model,
gaudi_config=gaudi_config,
# The training arguments differ a bit from the original ones, that is why we use GaudiTrainingArguments
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
data_collator=data_collator,
)
PyTorch Lightning 与 Gaudi®
PyTorch Lightning 是一个基于 PyTorch 构建的轻量级框架,提供 API 来抽象 PyTorch 用户训练模型所需的样板代码。Habana 一直在与 Grid.ai 合作,希望让开发人员能够更轻松、更快速地使用 PyTorch Lightning 在 Gaudi® 处理器上进行训练,而无需更改任何代码。Grid.ai 和 PyTorch Lightning 能够简化神经网络编码,而 Habana® Gaudi® 则可提高神经网络的训练效率。Habana 的 SynapseAI® 软件套件与 PyTorch Lightning 的集成将两者的优点结合在一起,提高了开发人员的工作效率,降低了模型训练的成本。近期发布的 PyTorch Lightning 1.6 现可支持 Habana® Gaudi®。开发人员可以灵活地选择 Gaudi® 的 AI 算力和 PyTorch Lightning,快速、轻松地利用 Gaudi® 的优势。
从下图可以看出,使用 PyTorch Lightning 可以很方便地开启在 Gaudi® 上的训练:
import pytorch_lightning as pl
from pytorch_lightning.plugins import HPUPrecisionPlugin
trainer = pl.Trainer(accelerator="hpu”, devices=8, precision=16)
您只需为 Trainer 类提供 accelerator=”hpu” 参数,并通过设置设备参数来选择 Gaudi® 处理器的数量。要进行混合精度训练,导入 HPUPrecisionPlugin 并设置 “precision=16” 即可。
MLOps 与 cnvrg.io
cnvrg.io 是由数据科学家构建并为数据科学家服务的机器学习平台。该平台正在改变企业从研究到生产这一过程中管理、扩展和加速 AI 及数据科学的方式,并提供在本地和/或云端运行的出色灵活性。Habana 和 cnvrg.io 携起手来,为数据科学家和 AI 开发人员带来二者的优势,既提高了 AI 训练的灵活性和效率,又降低了 AI 训练的成本。企业现在可以借助 cnvrg.io MLOPs 平台轻松部署 Gaudi® 的 AI 算力,同时获得成本效益。
借助 cnvrg.io,数据科学家可以通过拖放机器学习流水线来部署更多模型。您可以轻松运行和跟踪实验,并利用可重复使用的组件和拖放界面实现从研究到生产的机器学习自动化。在 cnvrg.io 上初次使用 Habana® Gaudi® 时首先需要为本地 Gaudi® 服务器设置 Kubernetes 集群,或者设置使用 DL1 EC2 实例的 Amazon EKS 集群。cnvrg.io 可无缝集成本地和云端的计算资源。托管 SynapseAI TensorFlow 和 PyTorch Docker 容器映像的 Habana Vault 已集成至 cnvrg.io 注册表,可从该注册表获取。您可以启动新的 Jupyter 工作空间,从 cnvrg.io Habana 容器注册表中选择合适的 Gaudi® 计算映像和 Docker 映像。然后,只需在 cnvrg Project Settings Git Integration(项目设置 Git 集成)页面中添加存储库位置即可开始使用 Habana 参考模型。至此,您就可以在 cnvrg.io 中开始新实验和在 Gaudi® 上训练您的模型了。
为高性能、高效率的深度学习处理器设计和开发硬件只是 Habana 的一小部分工作;Habana 主要致力于利用这些硬件以及您所需要的合适软件、工具和支持,让您的工作负载和模型能够高效、准确、快速地运行。
除了专为满足性能和可用性要求而设计的 SynapseAI® 软件套件之外,我们还发布了大量信息,提供了大量资源,方便您在 Gaudi® 处理器上开始训练。Habana 开发人员网站是 Habana 开发人员的帮助中心。在这里,您会找到轻松灵活地构建新 AI 模型或迁移现有 AI 模型,以及优化模型在 Habana AI 处理器上的性能所需的内容、指导、工具和支持。



