HDD的每TB带宽一直在下降。这迫使数据中心工程师通过将热(频繁访问的)数据转移到TLC闪存层或过度配置存储来满足其存储性能需求。
继续阅读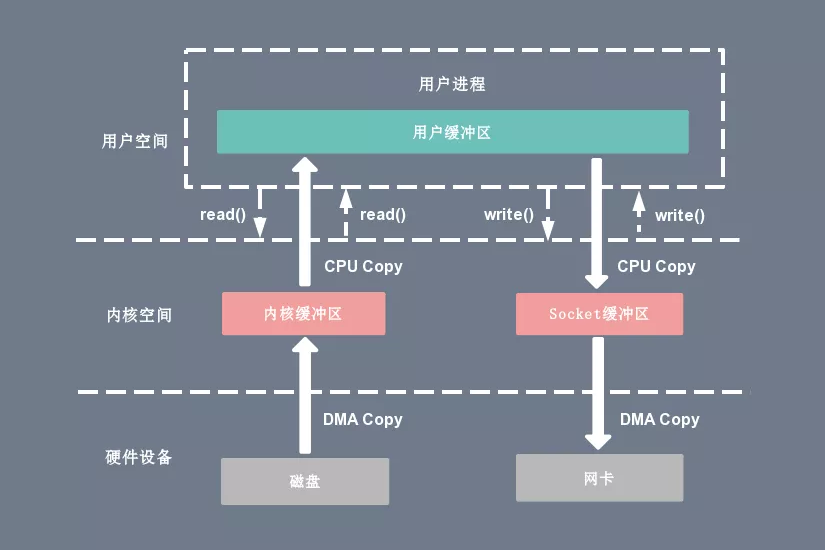
深入理解 Linux 的 I/O 系统
在 Linux 系统中,传统的访问方式是通过 write() 和 read() 两个系统调用实现的,通过 read() 函数读取文件到到缓存区中,然后通过 write() 方法把缓存中的数据输出到网络端口。
继续阅读Google AI TPU






在 Linux 系统中,传统的访问方式是通过 write() 和 read() 两个系统调用实现的,通过 read() 函数读取文件到到缓存区中,然后通过 write() 方法把缓存中的数据输出到网络端口。
继续阅读
AMD 今天宣布推出期待已久的 MI300X 加速器芯片,AMD 打算成为 NVIDIA 旗舰 H100 GPU 的有力竞争对手。
继续阅读AI/ML正在如何重塑企业内部的技术权力结构。
继续阅读
基于HBM3E,H200带宽可达4.8TB/s(比H100的3.35TB/s提升43%),并且内存容量从80GB提升至141GB,这使得H200成为高性能计算(HPC)和人工智能等领域的理想选择。
继续阅读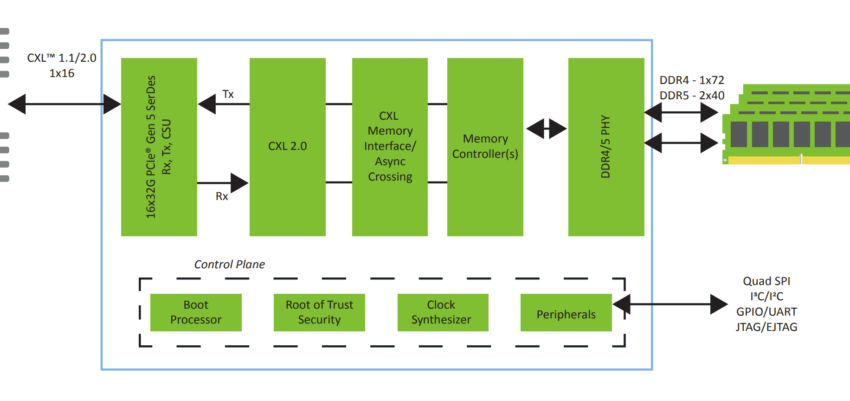
数据中心工作负载变得越来越复杂,需要越来越多的内存。内存是一种非常昂贵的资源,预计到 2025 年将达到服务器价值的 40% 以上。
继续阅读随着NVMe技术迅速发展成为高速存储驱动接口的新标准,SAS将在未来的多年中继续保持其存在,因为其拥有庞大的已安装基础。
继续阅读LPDDR的特点很明显,低功耗、体积小。它主要的应用场合是各种智能手机、平板电脑、电视盒子、嵌入式设备等。
继续阅读
关于CPU缓存的由来,最早是在1964年IBM公司推出的一款大型老古董计算机–360/85中首次使用,就是下图这个大家伙。
继续阅读