
读了那么多CXL相关文章,却依旧不理解为什么CXL可以解决缓存一致性问题的原理。这是我最近最新的一些感受,因为从CXL在2022FMS出圈到现在也已经过去一年多时间,其间也拜读了一些专家的文章,但始终没有更深层次的了解。
某一天,笔者突然想,CXL所说的缓存一致性到底是什么,又是如何解决的呢?似乎一直以来没有人告诉我们,于是便有了今天这篇文章,让我们一起来扒拉一下其中的奥妙。
今天的文章,将会从以来几个角度来探讨CXL的缓存一致性解决思路,分别是:
- 什么是缓存一致性?如何产生的?
- CXL如何解决缓存一致性问题?
什么是缓存一致性
关于CPU缓存的由来,最早是在1964年IBM公司推出的一款大型老古董计算机–360/85中首次使用,就是下图这个大家伙。说是当年IBM为了研发这款计算机,召集了6万多人,新建了5家新工厂,最后还是不断延期交付,可见人类的重大创新从来都不是轻轻松松能够完成的。
随后Intel便在其386平台CPU开始引入SRAM缓存,当然容量是非常小的,最大才64KB。但很快人们发现,缓存容量太小跟不上CPU的技术发展,但是容量增加又会降低性能,因此多级缓存应运而生。现代CPU基本是L1,L2,L3三级缓存架构,L1离CPU最近性能最高但容量很难提升,L3离CPU最远离Memory最近性能最低但容量更容易提升,这样既可以满足容量需求,又可以满足性能需求,一举两得。
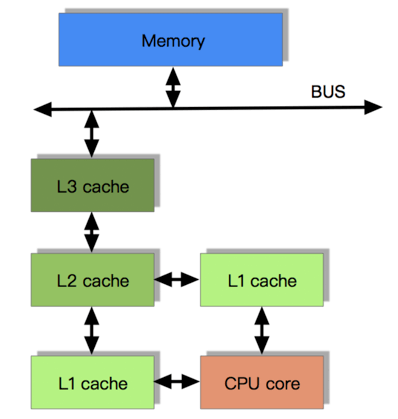
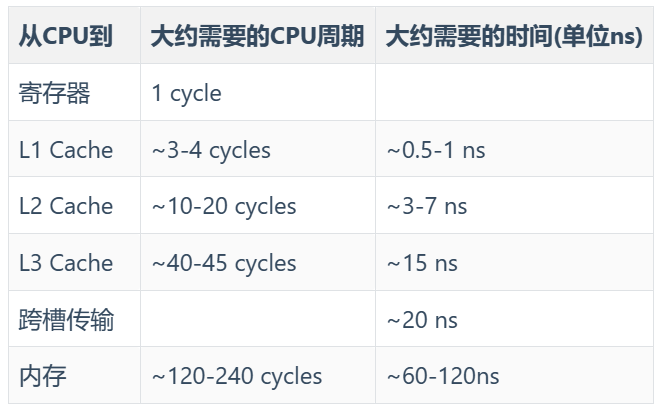
下图是3级缓存架构对应的处理速度:
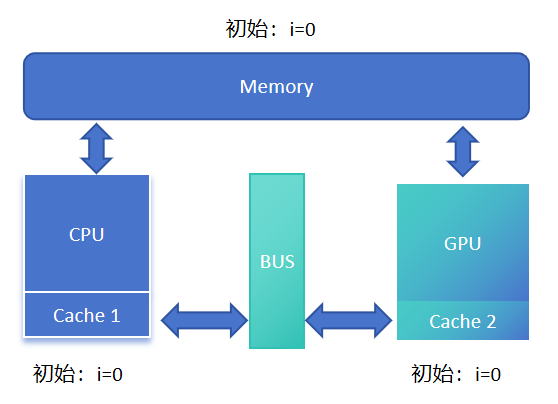
言归正传,下面来看一下缓存一致性问题是如何产生的。
在一个异构服务器系统中,假设CPU和GPU对应的缓存分别是Cache 1和Cache 2,在某个程序中,CPU和GPU同时操作变量i,初始值都是0。
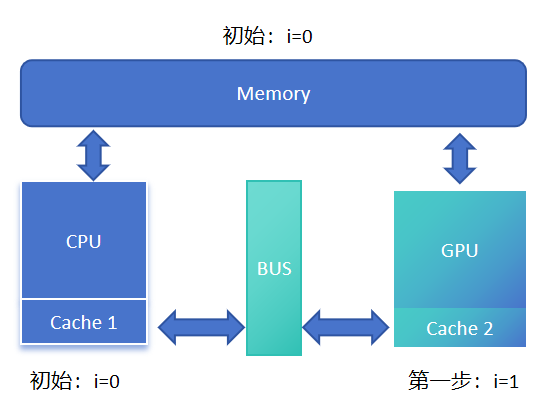
第一步,当GPU对变量i进行某个运算后,得到运算结果1,这时候GPU将Cache 2中变量i修改为1。
但是,在多数情况下,为了提高系统性能,内存操作策略被配置为write back,write back策略大大减少了数据写到Memory的频率,大部分情况数据只保留在Cache中并在Cache中被更新。
此时,如果CPU从Memory中读取变量i的值,那么它读到的是错误的值,因为GPU对变量i最新的操作并没有写入内存,内存中i的值依旧是0。这就是我们常说的缓存一致性问题,CPU和GPU各自的Cache在这时候出现了不一致,导致程序运行出错。
CXL如何解决缓存一致性问题
那既然存在缓存一致性问题,该如何解决呢?CXL协议又是如何解决的?
CXL引入3大杀器,分别是Asymetric Protocol、Snooping和MESI。
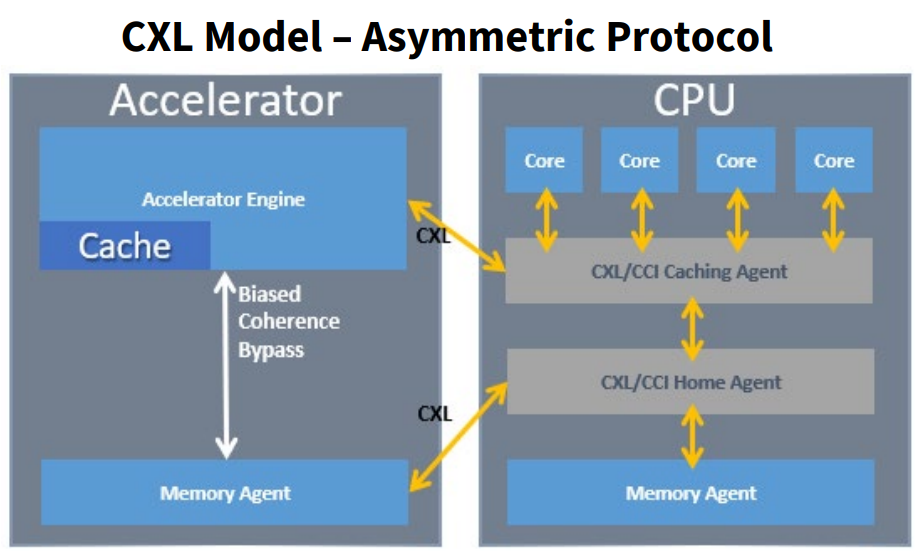
Asymetric Protocol(非对称协议)
非对称协议,顾名思义,不同于常规的对称结构,基于非对称架构,CXL将硬件形式的Cache agent和Home agent内置于CPU之中,Host即可利用Cache agent和Home agent直接通过CXL BUS访问外设的Cache和Memory。小编能力有限,具体的实现技术细节这里不展开了,其中还涉及到Host Bias、Device Bias这两种实现方法,做研发的小伙伴可以下载官方资料再深入琢磨一下。
总结起来,就是相比对称协议,非对称协议更加简单,延时更低,让各种外设处理器和CPU可以更好地成为一个高效的系统,大大促进了异构计算的发展进程。
Snooping(嗅探)
Snooping,翻译过来是监听、侦听的意思,字面意思可能比较不容易理解,意思是当某个CPU更新了Cache,要把信息广播到其他处理器(CPU/GPU)让BUS上所有处理器都知道这个信息。
这个理解起来相对就简单多了,第一节不是说到缓存一致性问题发生的原因嘛。因为GPU修改了变量i,但是CPU并不知道,直接从Memory获得的变量i仍旧是老的值,现在好了,我GPU修改了变量i,给你CPU发个微信说一声:“嘿,老王,我刚刚把变量i从0改成1了,请查收,over”。隔壁老王CPU收到了GPU的消息,赶紧把自己的Cache中变量i也改成1,同时写到Memory。
其实可以发现,这个过程还是比较简单的,只要任何一个隔离的老王、老李、老孙修改了变量i,他都要给所有楼层的邻居发个消息说一声,通知一下大家。
但这需要BUS上每个处理器都要每时每刻监听总线上的变化,这无疑加深了处理器的负载。整个楼层的人都要每时每刻盯着手机微信,决不能错过一条邻居的消息,天天被老婆骂:“死男人,天天盯着个手机看,家务活也不知道干!气死老娘了”。怎么办呢?
解决方案来了,那就是MESI!
MESI
MESI(该协议由伊利诺斯州立大学提出,因此又被称为伊利诺斯协议)是一种广泛使用的支持写回策略的缓存一致性协议。
该协议的出现就是为了解决前面我们说的多个CPU缓存一致性问题和多处理器监听资源占用问题,MESI通过对缓存行(Cache Line)的数据进行4种不同状态的标记,分别是:
- Modified,已修改
- Exclusive,独占
- Shared,共享
- Invalidated,已失效
看上去像是一堆表示状态的形容词,没错,可以把它理解为一种状态机。
「已修改」状态代表该 Cache Block 上的数据已经被更新过,但是还没有写到内存里,因此和内存中的数据不一致。在Snooping嗅探机制下,如果有其他处理器要去读该状态的Cache Block数据,则会发生一定的延时,需要等到该Block数据写入内存,并将Cache Line标记为S(共享)状态之后去读。
「独占」和「共享」状态都表示该Cache Block 里的数据是可用的,没有被修改过的,所以它们和内存里面的数据是一致的,意味着其他处理如果想要读该数据,可以直接读,效率非常高。
那「独占」和「共享」它们之间的区别又在哪里呢?
「独占」状态表示,该Cache Block数据只存储在某一个处理器核心的 Cache 里,而其他处理器核心Cache是没有这个数据的,也就是某一个处理器独有该数据。那在Snooping嗅探机制里,如何体现高效呢?因为是独占的数据,其他处理器Cache中都没有这个数据变量,那如果其他处理器要想修改这个数据或者读取这个数据,我直接把这笔数据给修改了或者直接读就可以了,也不用通知其他处理器了,是不是就很简单高效了。举个栗子,如果整个楼层只有你老王爱吃西瓜,其他邻居都不吃,我放在门口的西瓜丢了,我是不是可以直接锁定目标–去老王家找找,不用去挨家挨户地找了,效率大大提升有木有?
补充一点,当「独占」状态下的数据,如果有其他处理器从内存读取了该「独占」状态的数据到各自的 Cache ,那这个时候该数据就不再是「独占」状态,会变为「共享」状态。还是以隔离老王为例,本来这个楼就只有老王爱吃瓜,突然有一天有其他邻居搬进来了,新搬来的邻居也爱吃瓜,那我的瓜丢了,怀疑的目标是不是就多了?(比喻可能不太恰当,主要为了帮助理解)
「共享」状态比较容易理解了,它表示相同的数据在多个处理器核心的 Cache 里都存在,所以当BUS上其中一个处理器A想要更新 Cache 里面的数据的时候,就不可以再直接修改了,而是要先向所有的其他处理器发个广播告知一下,我要修改这个数据了,你们手上的数据可以作废了,其他处理收到消息后会将该位置 Cache 中对应的 Cache Line 标记为「无效」状态,然后处理器A再更新当前 Cache 里面的数据,此时该Cache Line会被标记为「独占」,其他处理想要继续保留的话,只能重新从处理器A对应的Cache中来复制过去。
「已失效」状态,顾名思义,指的是这个 Cache Block 里的数据已经是无效的被废弃的,无需再读取该状态的数据。
总结
都说艺术来源于生活,确实科技有时候也是这样,很多技术的解决方案和思路,很多都是来自于我们生活中的智慧点滴。希望今天读者,读完这篇文章,可以有所收获,对缓存一致性问题有个初步的了解。