CXL(计算快速链接)是一种开放的行业互连标准,可在主机处理器和设备(如加速器、内存缓冲区和智能I/O设备)之间提供高带宽、低延迟连接。它旨在通过人工智能、机器学习、分析、云基础设施、网络和边缘云化、通信系统和高性能计算等应用来支持异构处理和内存系统,从而在基于PCIe的I/O语义之上实现一致性和内存语义,从而满足不断增长的高性能计算型工作负载,从而在不断发展的应用模型中优化性能。这一点越来越重要,因为这些新兴应用中的数据处理需要在CPU、GPU、FPGA、智能NIC和其他加速器中部署标量、矢量、矩阵和空间架构的多样化组合。
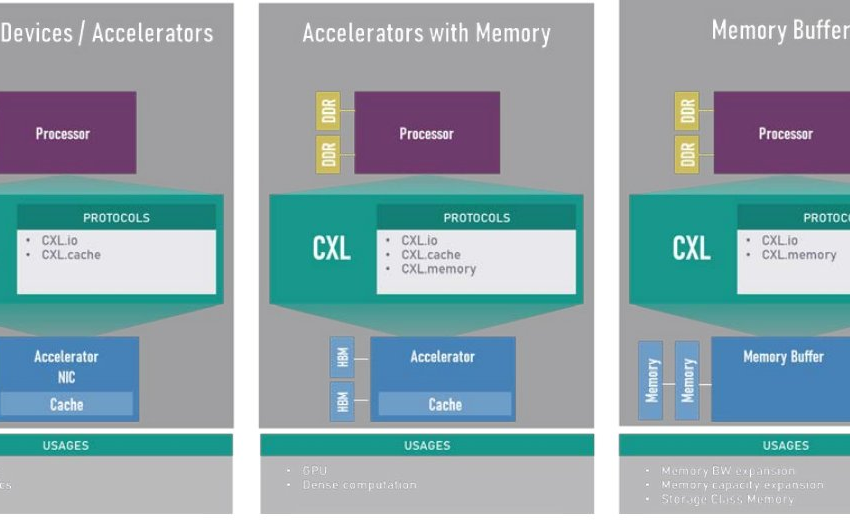
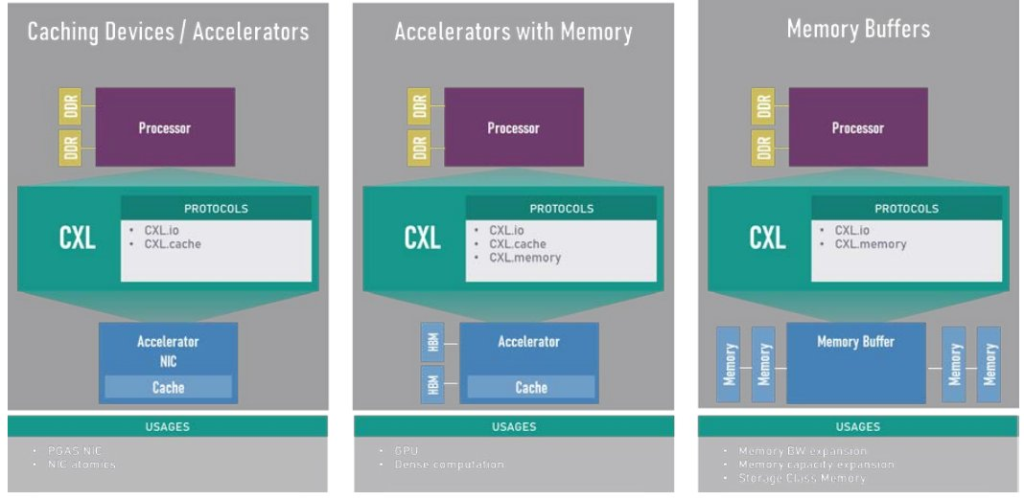
CXL 1.0于2019年3月首次亮相,支持在一组丰富的协议之间进行动态多路复用,其中包括I/O(CXL.io,基于PCIe)、缓存(CXL.cache)和内存(CXL.memory)语义。CXL在CPU(主机处理器)和所连接的CXL设备上的任何内存之间维护一个统一、一致的内存空间。允许CPU和设备共享资源并在同一内存区域上运行,以实现更高的性能、更少的数据移动和软件堆栈的复杂性,从而实现三种主要用途,如图1所示。
CXL 1.0于2019年3月首次亮相,支持在一组丰富的协议之间进行动态多路复用,其中包括I/O(CXL.io,基于PCIe)、缓存(CXL.cache)和内存(CXL.memory)语义。CXL在CPU(主机处理器)和所连接的CXL设备上的任何内存之间维护一个统一、一致的内存空间。允许CPU和设备共享资源并在同一内存区域上运行,以实现更高的性能、更少的数据移动和软件堆栈的复杂性,从而实现三种主要用途,如图1所示。
CXL 2.0以CXL的行业成功和接受度为基础,180多家成员公司的积极参与证明了这一点,CXL 2.0于2020年11月发布,支持额外的应用模型,同时保持与CXL 1.1和CXL 1.0的完全向后兼容性。CXL 2.0在三个主要方面增强了CXL 1.1体验:支持单级交换机、支持持久性内存、内存池和安全性。这些功能使平台中的许多设备能够迁移到CXL,同时保持与PCIe5.0的兼容性和CXL的低延迟特性。
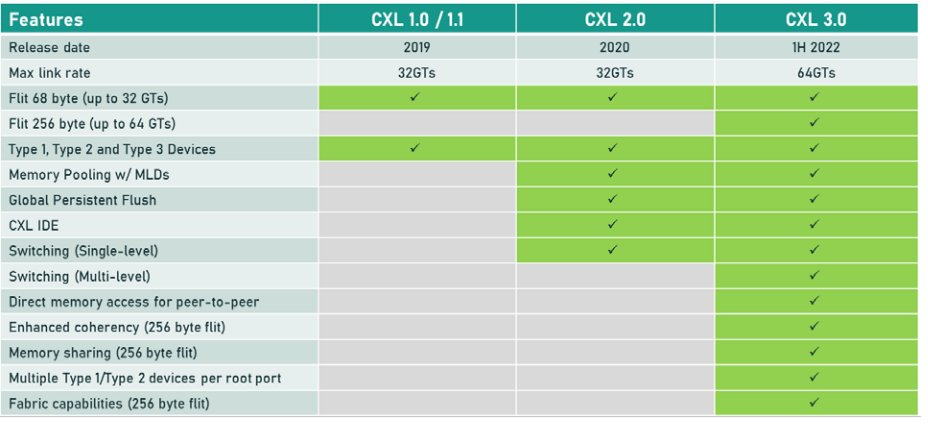
基于CXL 2.0的巨大成功以及计算机行业和最终用户社区的反馈,CXL联盟勇往直前,定义了下一代规范,以提供更高的性能并涵盖更多场景。由此产生的CXL 3.0规范是一项重大修订,它释放了变革性技术和用途的潜力!图2总结了CXL规范的过程,包括主要的增强和功能。
基于PCIe 6.0技术的CXL 3.0将传输速率翻倍至64 GT/s,与前几代产品相比,没有额外的延迟。这允许x16宽度链路的总原始带宽高达256 GB/s。对于低延迟传输,CXL 3.0利用PCIe 6.0的轻量级FEC和强CRC的组合,在PAM-4信令上具有256B信号传输以实现64 GT/s,从而实现64 GT/s。然而,CXL 3.0进一步引入了延迟优化的flit变体,通过将CRC分解为128B子流量粒度传输来进一步减少2-5ns的延迟,从而减轻存储和存储物理层中的开销。与前几代CXL一样,新的256B动态格式向后兼容8 GT/s、16 GT/s和32 GT/s,从而简化了向CXL 3.0的过渡。
CXL 3.0的256Bflit提供更大的空间与双倍的信令速率相结合,实现了许多协议增强功能,从而解锁了多个场景,我们将在下面简要介绍其中一些场景。
增强的一致性:对于具有内存的加速器(参见图1),通常称为CXL Type2设备,CXL 3.0中的一个主要增强功能是能够使主机的缓存失效。这种保持主机托管设备连接内存(HDM)一致性的模型称为增强一致性,取代了前几代中引入的基于偏差的一致性。通过对称一致性,Type-2设备可以为HDM地址范围实现Snoop滤波器,从而能够比以前更有效地映射和管理大量内存。此外,CXL 3.0中引入的增强一致性语义还支持直接对等访问HDM内存,而无需通过主机,并且 Type-2/Type-3设备能够通过主机处理器反向使缓存失效。后者将在下一节中更详细地介绍。
内存池化和共享:CXL 3.0对CXL 2.0中首次引入的内存池进行了重大增强。内存池是将CXL连接的内存视为可替代资源的能力,可以根据需要灵活地分配和释放到不同的服务器(也称为节点或主机)。这使系统设计人员在获得最佳性能的同时,不会过度配置机架中的每个服务器。图3显示了CXL 2.0内存池的示例。
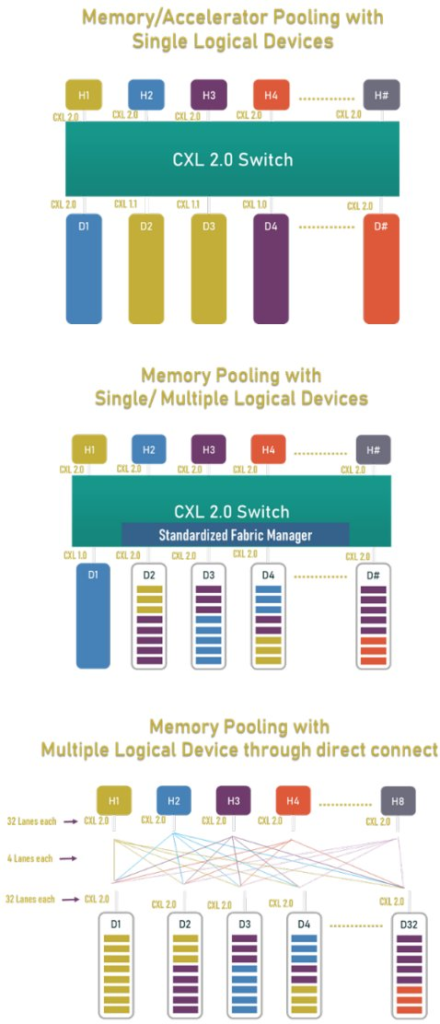
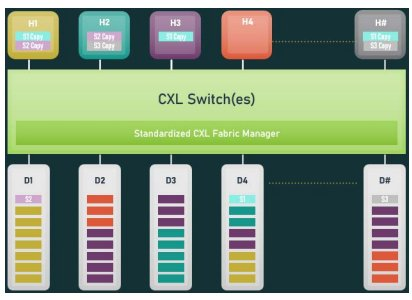
在CXL 3.0中,除了内存池之外,我们还引入了内存共享的概念。内存共享是CXL连接的内存使用硬件一致性在主机之间一致共享的能力。因此,与内存池不同,内存共享允许多个主机同时访问给定的内存区域,并且仍然保证每个主机都能看到该位置的最新数据,而无需软件管理的协调。这允许系统设计构建机器集群,以通过共享内存结构解决大问题。共享和池化内存拓扑的示例如图4所示。
Fabrics:CXL 3.0首次引入了fabric功能,超越了PCIe和前几代CXL的传统树基架构结构。图5显示了CXL fabric的一个非树拓扑示例。
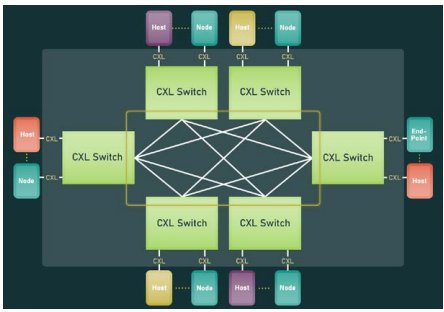
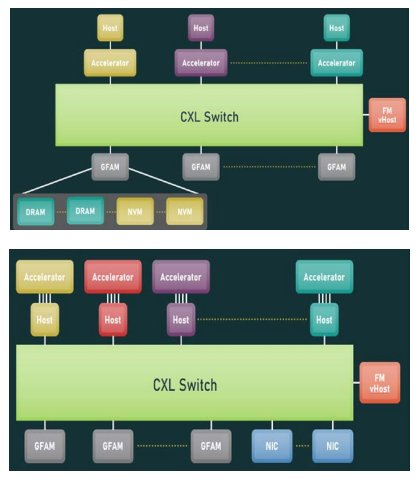
CXL fabric可以支持多达4096个节点,这些节点可以使用称为基于端口的路由(PBR,Port Based Routing)的新的可扩展寻址机制相互通信。此处,节点可以是CPU主机、带或不带内存的CXL加速器、PCIe设备或全局结构连接内存(GFAM,Global Fabric Attached Memory)设备。GFAM设备类似于传统的CXL Type-3设备,只是它可以使用基于端口的路由以可排序的方式由多个节点(最多4095个)访问。这种架构为构建强大的系统开辟了一个充满可能性的世界,该系统由计算和内存元素组成,这些元素的排列可以满足特定工作负载的需求。图6显示了CXL fabric的几个示例场景。
CXL 3.0标志着CXL联盟加速行业计算、内存和结构架构之旅的一个重要里程碑。凭借一系列令人兴奋的新功能,CXL 3.0为计算机架构的创新提供了新的动力。CXL将继续满足行业的新要求和反馈,并提供更高的性能和价值。





