
数字化潮流以一刻不停的速度深刻渗透到我们的日常生活之中。为了与消费者的期望保持同步,企业正日益倚赖机器学习算法,以实现事务更加的简捷化。这一趋势清晰地展现在社交媒体领域(例如图像中的物体识别技术),或者人们与设备之间的无缝交互中(如Alexa或Siri等智能助手)。
尽管人工智能(AI)、机器学习(ML)、深度学习以及神经网络等技术存在联系,然而在实际应用中,这些术语往往被交替使用,从而引发了人们对于它们之间区别的疑惑。本文将剖析其中的概念模糊之处。
人工智能、机器学习、深度学习和神经网络之间有何关系
以渐进式的层次将人工智能、机器学习、深度学习和神经网络的关系进行思考,最为简洁而直观。
从宏观来看,人工智能是这个体系的总引领。而在这之中,机器学习作为其子集,为其注入智能的精华。深度学习则进一步细分为机器学习的一个子领域,而神经网络则在深度学习算法中扮演了不可或缺的核心角色。就如同神经网络中的层级数量,或者说“深度”,区分了一个普通的神经网络和一个必须拥有超过三层的深度学习算法。
什么是人工智能(AI)
在这三个术语之中,人工智能被视为最广泛的概念,它扮演着模拟人类智能和认知功能的机器的角色。人工智能通过预测和自动化的手段,致力于优化和解决那些历来由人类完成的复杂任务,诸如面部和语音识别、决策制定以及语言翻译等。
AI的类别
人工智能有三个主要类别:
- 狭义人工智能(ANI,Artificial Narrow Intelligence)
- 通用人工智能(AGI,Artificial General Intelligence)
- 超级人工智能(ASI,Artificial Super Intelligence)
在具体分类上,狭义人工智能被视为“弱”人工智能,而其它两种类型则被划分为“强”人工智能。我们将弱人工智能定义为其在特定任务上的执行能力,譬如在国际象棋比赛中获胜,或在一系列照片中识别出特定个体。同时,自然语言处理(NLP)以及计算机视觉也为企业赋予了自动化任务的能力,并且为虚拟助手如Siri和Alexa等提供了支撑。这两者均为狭义人工智能(ANI)的实例。此外,计算机视觉在自动驾驶汽车的发展中也扮演了关键角色。
更为强大的人工智能形态,如AGI和ASI,更加深入地融汇了人类行为,诸如解读语气和情感的本领。强人工智能的界定则依赖于其相对于人类的能力。通用人工智能(AGI)将能够与另一个人类表现相媲美,而超级人工智能(ASI)——也被冠以超级智能之名——将超越人类的智能和潜能。虽然这两种形态的强人工智能目前尚未问世,但在这个领域的研究依然蓬勃进行中。
企业运营中的人工智能应用
如今,全球大约有35%的企业正在积极应用人工智能,而另外42%则在积极探索这项前沿技术。在这一背景下,生成式人工智能的崭露头角引发了广泛关注。该技术基于强大的基础模型,通过对大量未标记数据的训练,具备了适应新应用场景的能力,带来了更强的灵活性和可扩展性。从早期的实验中我们可以看到,生成式人工智能相较传统方法,能将价值创造时间提高70%。
无论是基于机器学习(ML)构建的应用,还是基于基础模型的人工智能应用,都可以在业务中带来巨大的竞争优势。将定制化的AI模型融入到工作流程和系统中,自动化客户服务、供应链管理以及网络安全等职能,不仅能够满足当下客户的期望,更能够迎合未来期望的提升。
然而,关键在于从最初就准确定位适合的数据集,以确保所使用的数据具备高质量,从而达到最大的竞争优势。同时,还需要打造一个能够兼容各种数据存储位置的混合架构,使得数据能够在主机、数据中心、私有云、公有云以及边缘设备之间流通自如。
最为重要的是,AI系统必须经得起信赖的考验,因为任何不符合标准的情况都可能导致公司声誉受损,甚至可能引发法规处罚。误导性模型以及带有偏见或产生虚假结果的模型,都可能对客户隐私、数据权益和信任造成极大的损害。因此,AI系统必须是可解释的、公平的,以及透明的。
什么是机器学习
机器学习,作为人工智能的一个分支,具备优化能力。在正确的设定下,它能够进行预测,从而最小化仅仅基于猜测所产生的误差。举例来说,像亚马逊这样的企业,通过机器学习可以根据用户之前浏览和购买的内容,为特定客户推荐产品,实现精准化营销。
在经典或被称为“非深度”的机器学习中,人的干预起到了决定性作用,使计算机系统能够识别模式、学习、执行特定任务,并提供准确的结果。人类专家对于特征的层次结构进行定义,以便理解数据输入之间的差异。这通常需要更加结构化的数据来进行学习。
以一个例子来说明,假设一系列不同类型的快餐图片,如“披萨”、“汉堡”和“塔可”。处理这些图片的人类专家会确定将每张图片区分为特定快餐类型所需的特征。食物类型中的面包可能是一个显著特征。或者,他们可能通过使用标签,如“披萨”、“汉堡”或“塔可”,从而通过监督学习简化了学习过程。
虽然被称为深度机器学习的AI子集可以通过带有标签的数据集在监督学习中为其算法提供信息,但它并不一定需要带有标签的数据集。它可以摄取非结构化数据的原始形式(如文本、图像),并且能够自动确定区分“披萨”、“汉堡”和“塔可”之间特征的集合。随着我们不断产生更多的大数据,数据科学家将会更加广泛地运用机器学习技术。
机器学习的第三类别则是强化学习,其中计算机通过与周围环境进行互动并获取反馈(奖励或惩罚),从而逐渐学会调整自身行为。在线学习则是机器学习的一种类型,数据科学家会在新的数据产生时更新机器学习模型,以确保模型持续适应不断变化的情境。
深度学习与机器学习的区别
正如我们在深度学习中详细介绍的那样,深度学习是机器学习的一个分支。然而,机器学习和深度学习之间存在着主要差异,主要体现在算法学习方式和所需数据量上。
深度学习在过程中自动化了大部分特征提取的环节,从而消除了许多需要人工干预的手动步骤。同时,它还能够应用于大规模数据集,因此被赋予了“可扩展的机器学习”之名。这一特性尤为引人注目,尤其是在我们探索非结构化数据应用的过程中,尤其因为估计超过80%的企业数据是非结构化的。
深度学习模型通过观察数据中的模式,能够将输入恰当地进行分类。以之前的示例为例,我们可以根据图像中的相似性或差异,将披萨、汉堡和塔可的图片分别归类。然而,深度学习模型需要更多的数据点以提高准确性,相对于需要较少数据的机器学习模型而言。通常情况下,企业将深度学习用于更为复杂的任务,如虚拟助手的开发或者欺诈检测的领域。
什么是神经网络
神经网络,又称人工神经网络(ANN)或模拟神经网络(SNN),是机器学习的一个分支,也是深度学习算法的核心所在。它们之所以被称为“神经”,是因为它们模拟了大脑中神经元之间的信号传递过程。
神经网络由多个节点层构成,包括输入层、一个或多个隐藏层以及输出层。每个节点都类似于人工神经元,与下一个节点相连,并带有权重和阈值。当某个节点的输出超过阈值时,该节点被激活,将数据传递到网络的下一层。相反,如果低于阈值,数据则不会传递。
训练数据让神经网络学习,并随着时间的推移提高其准确性。一旦学习算法进行微调,它们将成为强大的计算机科学和人工智能工具,因为它们使我们能够高效地对数据进行分类和聚类。借助神经网络,语音和图像识别任务可以在几分钟内完成,而不需要手动操作花费数小时的时间。谷歌的搜索算法便是一个众所周知的神经网络应用案例。
深度学习与神经网络之间有什么区别
正如前文所述,更值得特别强调的是,在解释神经网络时,“深度学习”中的“深度”指的是神经网络中的层数。一个由三层以上(包括输入和输出)组成的神经网络可以被视为深度学习算法。以下图表能够清晰呈现这一概念:
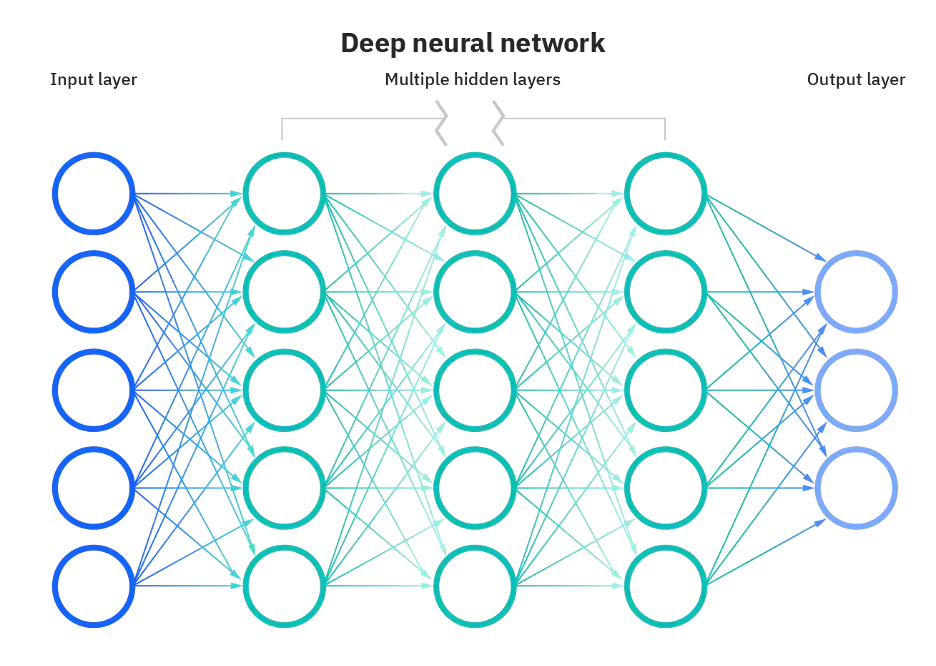
大多数深度神经网络都是前馈的,这意味着它们仅从输入向输出流动。然而,还可以通过反向传播来训练模型,即从输出向输入的方向移动。反向传播使我们能够计算并归因于每个神经元的错误,从而使我们能够适当地调整和拟合算法。
AI数据管理
尽管所有这些AI领域都有助于简化业务流程并提升客户体验,但实现AI目标可能会面临挑战,因为首先需要确保拥有适当的系统来构建学习算法以管理数据。数据管理不仅仅是用于构建业务模型的一环。需要一个存储数据的地方,并需要机制来清理数据并控制偏见,然后才能着手构建任何项目。在数据的管理和维护中,有着坚实的基础,才能在AI的道路上走得更远。







