
Nvidia发布了一份财务报告,其中包含新的Nvidia芯片路线图,囊括了GPU、GPU以及交换ASIC芯片。
首先回顾一下过去几年的路线图。这是来自2021年GTC(GPU技术大会)的路线图,当年是在4月举行的:
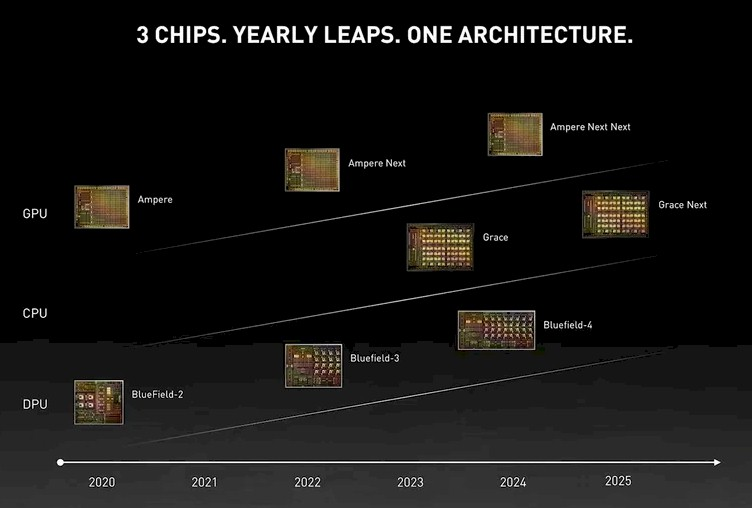
接下来是在“Hopper”发布之后更新的版本,之前路线图中称为“Ampere Next”,发布于2022年的Computex:
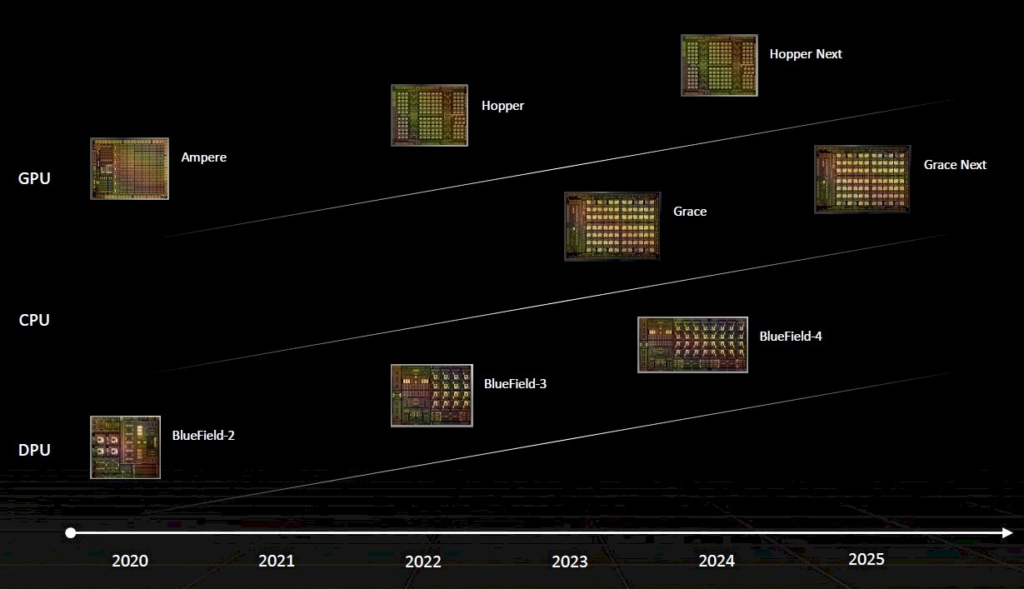
然后,这是今年初发布的路线图的更新版本,其中添加了用于AI推理、可视化以及元宇宙处理卡的“Lovelace”系列GPU:
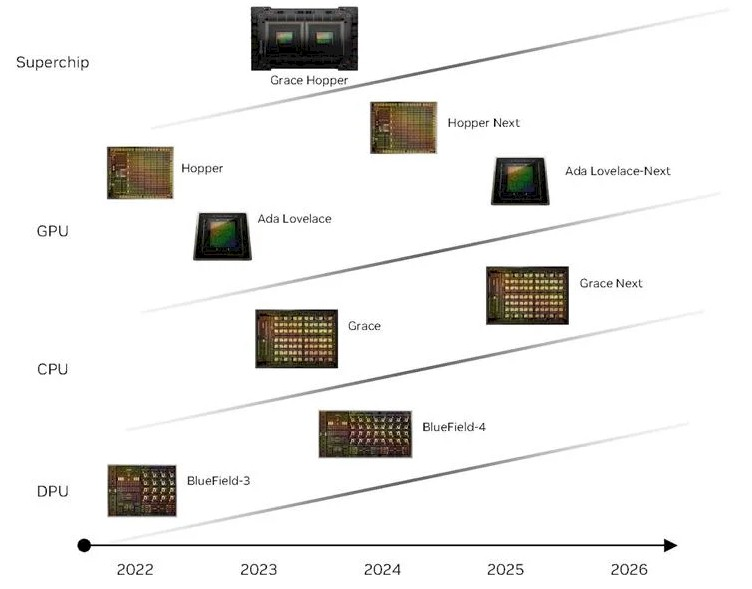
最后,这是Nvidia刚刚在十月初发布的路线图:
如果过去的趋势能够作为未来的参考——尤其是当芯片制造商承诺向超级计算和云服务商客户提供每两年一次的发布节奏时,就像Nvidia几年前所承诺的那样——那么我们绝对期望明年三月至五月之间能够看到全新架构的Blackwell GB100 GPU加速器。不过,正如下面的路线图所显示,Nvidia的重要GPU发布节奏通常要比两年更为频繁。因此,可以看作是一种回归。
以下是过去21年数据中心GPU的推出历史,这段时间内数据中心GPU计算变得至关重要:
- 2012年5月:”Kepler” K10和K20
- 2013年5月:”Kepler” K40
- “Kepler” K80,两颗GK210B GPU位于同一张卡上
- 2015年11月:”Maxwell” M40,主要用于AI推理,不太适用于HPC或AI训练
- 2016年4月:”Pascal” GP100
- 2017年5月:”Volta” GV100,某些Pascal的功能直到Volta才得以完全实现
- 2020年5月:”Ampere” GA100
- 2022年3月:”Hopper” GH100
- 2024年春季?:”Hopper-Next” H200
- 2024年夏季或秋季?:”Blackwell” GB100
- 2025年春季或夏季?:”Xavier” GX100
很明显,Hopper-Next原本应该是Blackwell GB100 GPU,而现在路线图上的GH200只是一种权宜之计,试图分散一些注意力,以防止人们过多关注即将在12月发布的AMD的“Antares” Instinct MI300X GPU和MI300A混合CPU-GPU设备。对于这些设备,AMD将享有HBM内存容量和带宽的优势,以及CPU和GPU的统一内存。而Nvidia无法声称H100NVL双卡是答案。
针对即将推出的Hopper-Next H200 GPU,有两种可选方向。我们更倾向于其中一种,尽管只是基于一种直觉。那就是让Nvidia尝试将两颗Hopper GH100 GPU放入同一个插槽中,就像他们已经在其Grace-Grace超级芯片中使用Arm服务器CPU一样。事实上,我们建议这样做已有一年半之久。这款芯片的性能可以适度降低,以获得更适宜的功耗范围,并为更高容量的HBM3e内存留出空间,从而提高数据中心中目前急需的内存与计算比例。
在GPU插槽中,芯片数量并非像每个插槽的带宽那般至关重要。尽管我们期望每个插槽内放置两颗GPU,但关键在于确保4、6或8倍的内存带宽,这才是真正提升GPU性能并领先于竞争的关键。我们提出这一点时或许是半开玩笑,也许采用半颗Hopper GPU,暂且称之为“Hop”,并提供2倍的内存容量和2倍的内存带宽会更有意义。
虽然有人认为H200的升级仅涉及内存,提供相同GH100 GPU的2倍内存容量和2倍内存带宽,但我们认为可能会有一些微调,至少在性能方面可能会进行更深度的细化。
然而,这份路线图中令人困扰的另一个问题是:根据Nvidia最新的路线图,那未来的Blackwell GB100 GPU和B100加速器究竟何时推出?您在上面看到日期了吗?我们推测它可能在2024年末发布,但也有可能延迟至2025年初。(我们认为Blackwell芯片很可能以Elizabeth Blackwell命名,她是美国第一位获得医学学位的女性,毕业于纽约州上部的日内瓦医学学院,现在是雪城大学的一部分,同时也是英国医学委员会的注册医生中的第一位女性。)
无论如何,Blackwell GB100 GPU和GX100 GPU——我们可以暂时称之为“Xavier”——将在2025年相继发布,我们猜测GX100可能会在年底发布,但也有可能不会。(我们找不到以X结尾的著名科学家,除了漫威超级英雄宇宙中的虚构人物Charles Xavier,是的,我们知道Nvidia已经在其中一个嵌入式系统上使用了那个代号。“X”可能只是表示它是一个变量,Nvidia还没有确定代号。)
我们认为Nvidia可能需要更多时间来调整Blackwell GPU的架构,考虑到AI模型变化迅猛,如果这对Nvidia来说非常重要,就像Volta时代的Tensor Cores、Ampere时代的稀疏支持、Hopper时代的Transformation Engine和FP8一样。这样的调整是合理的,也是必要的。
解决了这个问题后,我们对Nvidia当前的路线图有一些不满。例如,BlueField DPU去哪儿了?DPU是Nvidia硬件堆栈的重要组成部分,提供网络、安全和虚拟化卸载,将超级计算机转化为多租户云。Hopper GPU是在2022年春季GTC大会上宣布的,而不是在2023年,同时也在2022年末开始发货。然而,H100NVL和Lovelace L40却不见了。此外, “Ampere” A100是在2020年发布的,而不是在2021年。Quantum 2 400 Gb/s InfiniBand和400 Gb/s Spectrum-3以太网是在2021年公布的,并在2022年开始发货,而不是在2023年。此外,以太网和InfiniBand的800 Gb/s速度比我们在2020年11月与Nvidia交谈时预期的要晚一年左右。值得一提的是,之前一代的200 Gb/s Quantum InfiniBand于2016年公布,于2017年开始发货,这之间有着相当大的差距,就像其他一些公司在试图从200 Gb/s升级到400 Gb/s时一样。
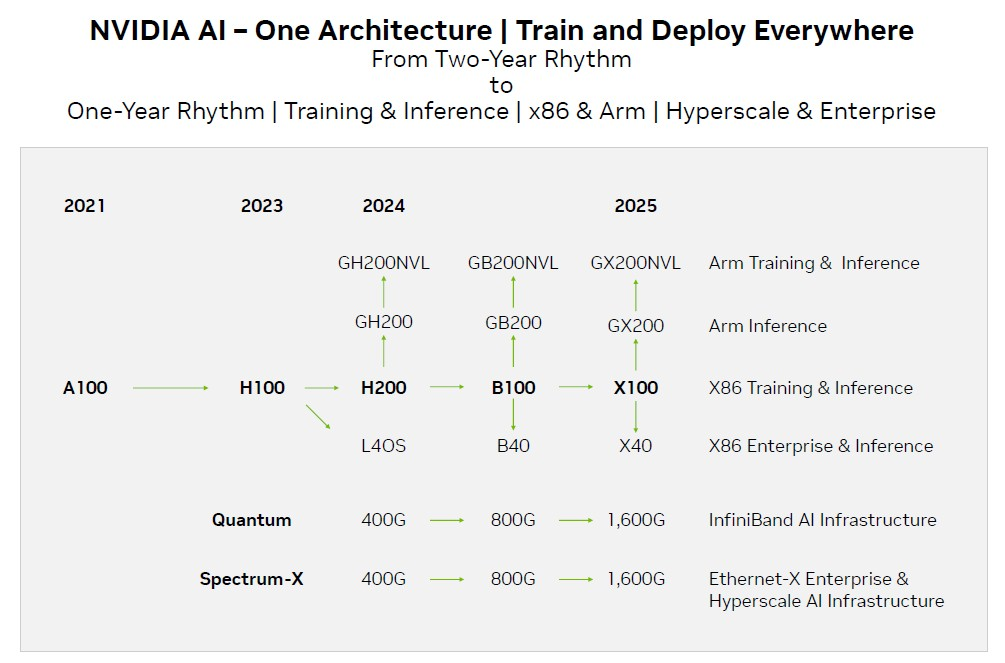
考虑到所有这些情况,因此我们对官方Nvidia路线图进行了更新,如下所示:

显然,生成式AI的爆发已经消除了数据中心和超级计算领域高层对计算和互联的犹豫。因此,每年发布一次的节奏是有道理的。但要在没有任何延误的情况下维持这个节奏可能会非常困难。实际上,这份路线图可以被视为一种遮掩,用以应对Blackwell架构交付的可能延迟。而Xavier GX100将在2025年发布,或许非常接近Blackwell,这表明有一些变化。也许Nvidia将从Blackwell开始切换到秋季发布和交付其数据中心GPU?不管H200 GPU加速器是什么,值得注意的是没有B200或X200跟随它。这个H200是一个“一招鲜”的产品。当然,除非Nvidia再次陷入困境…
有一点需要考虑:路线图的发布节奏并不像产品需求高达3倍、4倍,甚至可能达到5倍时供应量那样重要。如果云服务商和一些AI初创公司占据了所有的Hopper GPU,而其他人无法获得,那又如何呢?这意味着只要拥有矩阵数学引擎和AI框架的产品都有机会出售他们所拥有的任何东西。
因此,我们可以观察到这一情景正在逐渐显现,即使对于备受推崇的IntelGaudi加速器系列这样的产品,也发生了一些新变化。是的,Gaudi 2在性能上可以与英伟达的A100甚至H100媲美,而即将推出的Gaudi 3将提供2倍的性能,但这一切又有何不同呢?Gaudi 4并不存在,但有一款名为“Falcon Shores”的GPU,其中融合了Gaudi的矩阵数学单元和Gaudi的以太网互连。通常情况下,人们可能不会主动选择Gaudi 2。然而,在生成式AI的兴起浪潮下,任何具备矩阵数学单元的产品都可能会成为宝贵的资源。
因此,通过稍微研究了这份路线图,我们可以得出结论,这可能是最重要的一点。Nvidia拥有充足的资金来主导HBM内存和CoWoS基板市场,远超过那些同样需要这些组件来构建加速器的竞争对手。它可以获取即将推出的组件,例如台湾半导体制造公司提供的非常有意思的CoWoS-L封装技术,该技术允许芯片芯片之间采用相对传统的基板封装,但在需要高带宽连接的芯片芯片之间使用微型中间接头。(CoWoS-L有点类似Intel的EMIB)它有足够的资金来创建双芯片的H200和四芯片B100,如果愿意的话。Nvidia已经证明了四GPU设计的可行性,但公平地说,MI300X也表明AMD可以使用八个芯片片区堆叠在一个巨大的L3高速缓存之上。
Nvidia最好不要掉以轻心,因为在硬件领域,AMD绝不容忽视。那些热衷于开源框架和模型的人正在密切注视着PyTorch 2.0框架和LLaMA 2大型语言模型,出于Meta Platforms的自身利益,他们将不会受到任何阻碍。据称,PyTorch 在AMD 硬件上表现出色,而我们认为在 MI300A 和 MI300X 上的性能可能更上一层楼。
所以,Nvidia芯片的升级速度确实正在加快,从2024年正式开始进入每年一次的升级节奏。
请记住:你可以筑起护城河,但当井枯竭且水质可能受到敌人遗留物的影响时,你将无法享受其中的水。