AI 时代 GPU 成为核心处理器,分布式训练诉求提升。GPU 采用并行计算方式,擅长处理大量、简单的运算,因此多适用于图像图形处理和 AI 推理。但是大模型复杂度日益提升,单卡 GPU 显存有限,无法满足训练需求,比如百度文心一言大模型有 2600 亿个参数,但是实际上一个 80G 显存的 A800,算上训练中间的计算状态,只能存放 10-20 亿参数,存放 2600 亿的模型就需要 100-200 块 GPU;此外,后续大模型训练需要更多参数和更多计算,由此产生的 GPU 需求更为庞大。为适应算力需求,需要联合多张 GPU 甚至多台服务器协同工作,分布式训练成为核心训练方式。
网络连接在分布式系统中担任重要角色。网络在分布式系统中提供了连接作用,可以根据连接层级区分为单卡、多卡、多机互联,单卡内的网络为计算用的神经网,多卡之间的连接(即 GPU 互联)通常采用 PCIe 或各种高带宽通信网络,多机之间的连接(即服务器互联)通常采用 RDMA 网络。
总线是数据通信必备管道,PCIe 是最泛使用的总线协议。总线是服务器主板上不同硬件互相进行数据通信的管道,对数据传输速度起到决定性作用,目前最普及的总线协议为英特尔 2001 年提出的 PCIe(PCI-Express)协议,PCIe 主要用于连接 CPU 与其他高速设备如 GPU、SSD、网卡、显卡等,2003 年 PCIe1.0 版本发布,后续大致每过三年会更新一代,目前已经更新到6.0版本,传输速率高达64GT/s,16通道的带宽达到256GB/s,性能和可扩展性不断提高。
PCIe 总线树形拓扑和端到端传输方式限制了连接数量和速度,PCIe Switch 诞生。PCIe采用端对端数据传输链路,PCIe 链路的两端只能各接入一个设备,设备识别数量有限,无法满足有大量设备连接或需要高速数据传输的场景,因此 PCIe Switch 诞生。PCIe Switch 具备连接和交换双重功能,可以让一个 PCIe 端口识别和连接更多设备,解决通道数量不够的问题,并可以将多条 PCIe 总线连接在一起,从而形成一个高速网络,实现多设备通信,简言之 PCIe Switch 相当于 PCIe 的拓展器。
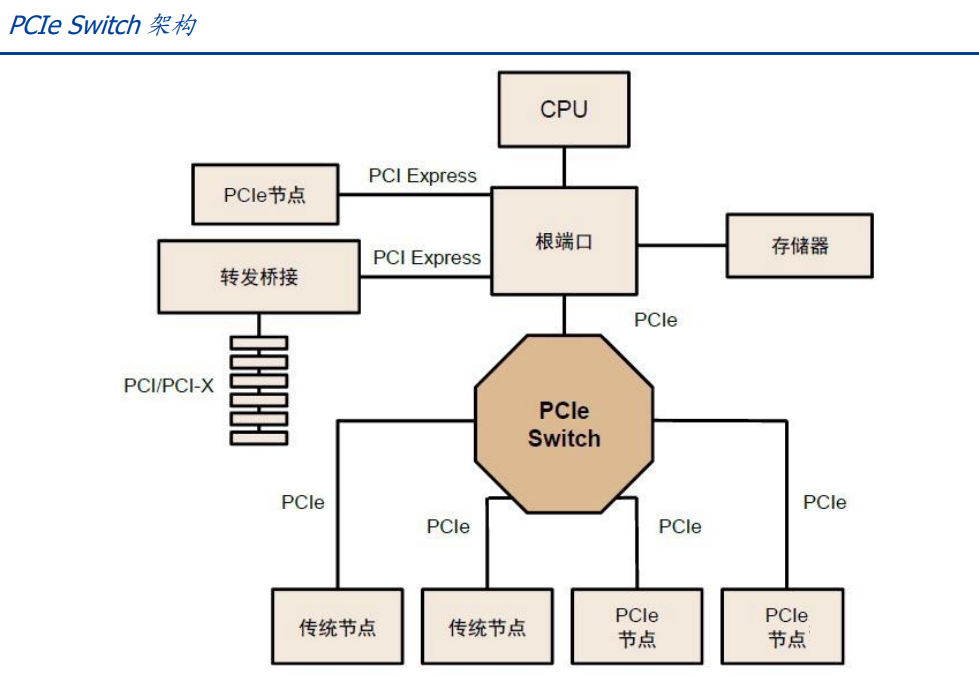
GPU 互 联 时 代 , PCIe 传 输 速 率 和 网 络 延 迟 无 法 满 足 需 求 ,NVLINK/CAPI/GenZ/CCIX/CXL 等“百家争鸣”时代开启。 AIGC 的发展极大刺激算力需求的增加,GPU 多卡组合成为趋势,GPU 互联的带宽通常需要在数百 GB/S以上,PCIe 的数据传输速率成为瓶颈,链路接口的串并转换会网络延时,影响 GPU 并行计算效率,还由于 GPU 发出的信号需要先传递到 PCIe Switch,PCIe Switch 涉及到数据的处理又会造成额外的网络延时,此外 PCIe 总线与存储器地址分离,每次访问内存会加重网络延迟,因此 PCIe 协议在 GPU 多卡通信中效率并不高。为了将总线通信效率提升,降低延时,各家纷纷推出替代协议:
CAPI 协议:由 IBM 最早推出,后逐渐演化成 Open CAPI,本质是现有高速 I/O 标准之上的应用程序扩展,添加了缓存一致性和更低延迟等内容,但由于 IBM 服务器份额的持续下降,CAPI 协议缺少用户基础,最终未能广泛流传。
GenZ 协议:GenZ 是不依赖于任何芯片平台的开放性组织,众多厂家参与其中包括AMD、ARM、IBM、Nvidia、Xilinx 等,GenZ 将总线协议拓展成交换式网络并加入GenZSwitch 提高了拓展性。
CXL 协议(陆续兼并上述两个协议):2019 年由 Intel 推出,与 CAPI 协议思路类似,2021 年底吸收 GenZ 协议共同发展,2022 年兼并 Open CAPI 协议,CXL 具备内存接口,逐渐成长为设备互连标准的重要主导协议之一。
CCIX 协议:ARM 加入的另一个开放协议,功能类似 GenZ 但未被吸收兼并。
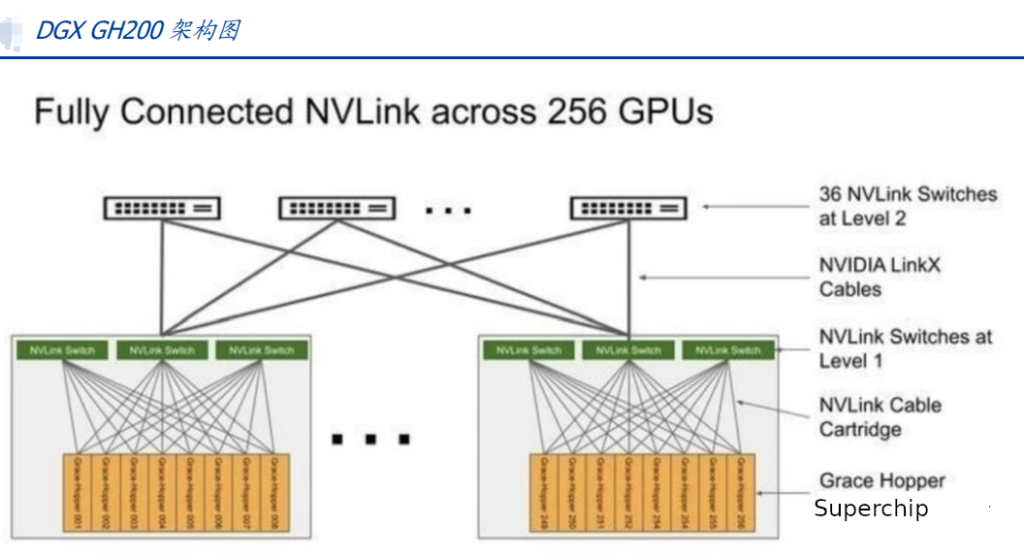
NVLINK 协议:英伟达提出的高速 GPU 互联协议,对比传统 PCIe 总线协议,NVLINK主要在三个方面做出较大改变:1)支持网状拓扑目,解决通道有限问题;2)统一内存,允许 GPU 共享公共内存池,减少 GPU 之间复制数据的需要,从而提高效率;3)直接内存访问,不需要 CPU 参与,GPU 可直接读取彼此的内存,从而降低网络延迟。此外,为解决 GPU 之间通讯不均衡问题,英伟达还引入 NVSwitch,一种类似交换机 ASIC 的物理芯片,通过 NVLink 接口将多个 GPU 高速互联,创建高带宽多节点 GPU 集群。2023 年 5 月 29 日,英伟达推出 AI 超级计算机 DGX GH200,通过 NVLink 和 NVSwitch 连接 256 个 GH200 芯片,所有 GPU 连接成一个整体协同运行,可访问内存突破 100TB。
多机互联:IB 网络与以太网络并存
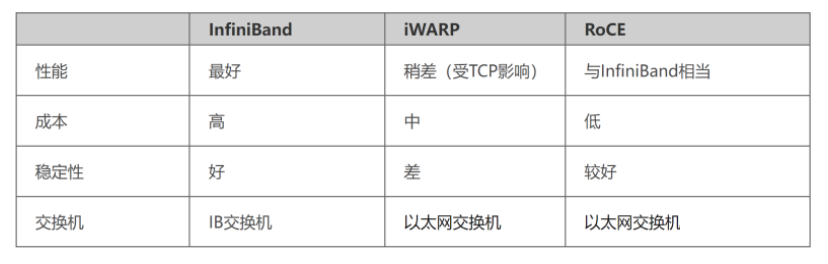
分布式训练下 RDMA 网络成为最佳选择,包含 IB 网络和以太网络。传统的 TCP/IP 网络通信是通过内核发送消息,涉及较多数据移动和数据复制,不适用高性能计算、大数据分析等需要 IO 高并发、低时延的场景。RDMA 是一种计算机网络技术,可以直接远程访问内存数据,无需操作系统内核介入,不占用 CPU 资源,可以显著提高数据传输的性能并且降低延迟,因此更适配于大规模并行计算机集群的网络需求。目前有三种 RDMA:Infiniband、RoCE、iWARP,后两者是基于以太网的技术:
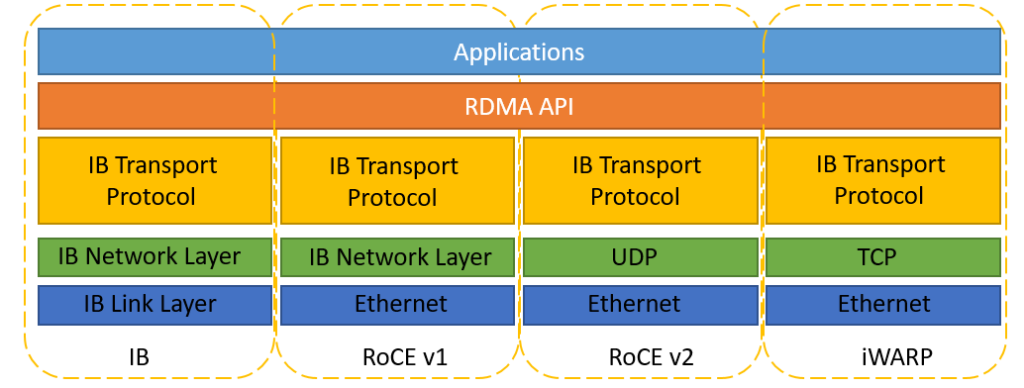
Infiniband:是专为 RDMA 设计的网络,从硬件级别保证可靠传输,具备更高的带宽和更低的时延。但是成本高,需要配套 IB 网卡和 IB 交换机。
RoCE:基于以太网做 RDMA,可以使用普通的以太网交换机,成本较低,但是需要支持 RoCE 的网卡。
iWARP:基于 TCP 的 RDMA 网络,利用 TCP 达到可靠传输。相比 RoCE,在大型组网的情况下,iWARP 的大量 TCP 连接会占用大量的内存资源,对系统规格要求更高。可以使用普通的以太网交换机,但是需要支持 iWARP 的网卡。