
AMD 和 Nvidia 都无意否认涉及 Instinct MI300X 和 H100 (Hopper) GPU 之间性能差异的争论。但 AMD 在使用 vLLM 比较 FP16 时确实提出了一些优点,vLLM 是与 FP8 相比更受欢迎的选择,而 FP8 仅适用于 TensorRT-LLM。
AMD于今年 12 月初发布了MI300X 图形加速器,声称比 Nvidia 的 H100 领先 1.6 倍。两天前,Nvidia 回击称,AMD 在将 H100 与 TensorRT-LLM 进行比较时没有使用其优化。在运行 Llama 2 70B 聊天模型时,回复到达了单个 H100 针对八路 H100 GPU 的情况。
基准结果和测试场景的持续
在最新的回应中,AMD 表示 Nvidia 使用了一组选择性的推理工作负载。它还进一步确定,Nvidia 使用 H100 上的内部 TensorRT-LLM 对这些进行基准测试,而不是 vLLM(一种开源且广泛使用的方法)。此外,Nvidia 在 AMD 上使用了 vLLM FP16 性能数据类型,同时将其结果与 DGX-H100 进行比较,后者使用具有 FP8 数据类型的 TensorRT-LLM 来显示这些所谓的误解结果。AMD强调,在其测试中,由于其广泛使用,它使用了带有FP16数据集的vLLM,而vLLM不支持FP8。
还有一点是,服务器会有延迟,但根据 AMD 的说法,Nvidia 并没有考虑到这一点,而是展示了其吞吐量性能,而不是模拟现实世界的情况。
AMD 更新了测试结果,通过 Nvidia 的测试方法进行了更多优化并考虑了延迟
AMD 使用 Nvidia 的 TensorRT-LLM 进行了三次性能测试,最后一次值得注意的测试是使用 FP16 数据集与带有 TensorRT-LLM 的 H100 数据集测量 MI300X 和 vLLM 之间的延迟结果。但第一个测试涉及在两者上使用 vLLM 进行比较,因此是 FP16,而对于第二个测试,它将 MI300X 的性能与 vLLM 进行比较,同时比较 TensorRT-LLM。
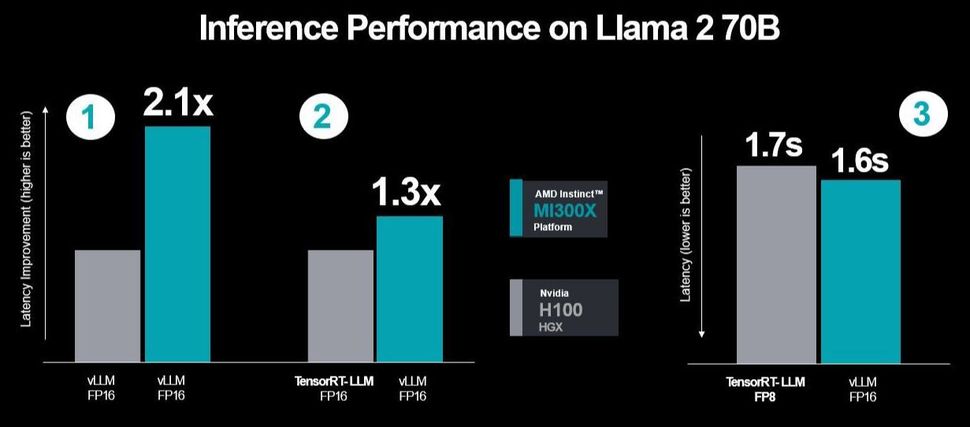
因此,AMD 使用了 Nvidia 在第二个和第三个测试场景中所选择的相同测试场景,显示出更高的性能和更低的延迟。与 H100 相比,该公司在两者上运行 vLLM 时添加了更多优化,性能提升了 2.1 倍。
现在由 Nvidia 来评估它想要如何应对。但也需要承认,这将要求业界放弃 FP16 和 TensorRT-LLM 的封闭系统,转而使用 FP8,从本质上来说,就是永远放弃 vLLM。在谈到 Nvidia 的溢价时,一位 Redditor 曾经说过,“TensorRT-LLM 是免费的,就像劳斯莱斯免费提供的东西一样罗。”






