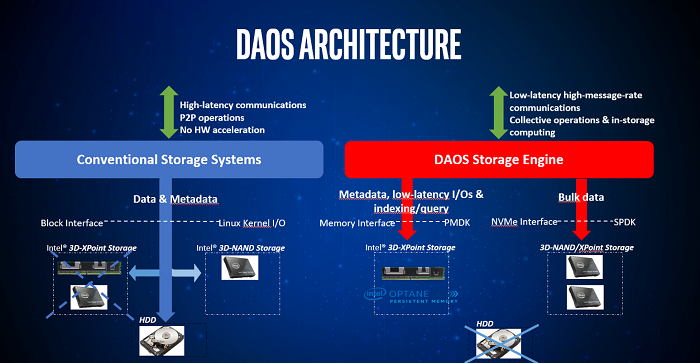
在传统情况下,分布式存储系统一直依赖于操作系统内核提供的接口与存储硬件进行交互。但是,大量研究表明,操作系统会对每个I/O操作产生相当大的开销,尤其是在使用高性能存储和网络硬件(如PMem和200GbE)时。因此,为了充分利用这些现代硬件的优势,分布式存储堆栈正在被重新设计,采用了一种完全绕过内核的新硬件接口。然而,这些优化在实际硬件上运行的真实高性能计算(HPC)工作负载下所产生的影响还没有得到深入的研究。
在本研究中,我们对DAOS进行了全面评估。DAOS是一种先进的分布式存储系统,它是专门为现代硬件重新设计的存储堆栈。我们将DAOS与传统存储堆栈进行了比较,并展示了通过充分利用硬件的最佳接口,DAOS在真实的科学应用中可以实现高达6倍的性能提升。
1 引言
在HPC系统中,由于存储和CPU性能之间的差距,长期以来一直受到I/O瓶颈的制约。为了弥补这一差距,HPC中心正在广泛部署高性能存储(例如PMem)和高速网络(例如200GbE)硬件。这些硬件通常按层次结构组织[8, 10, 18–20],其中数据首先缓存在高性能层,然后刷新到高容量层。尽管这些硬件进步为整体应用性能带来了显著的提升,但许多存储系统仍是在I/O明显滞后于计算的假设下设计的。随着研究的深入,这一假设不再成立,因为软件开销[16, 27, 34]和上下文切换[17, 23]等因素在各种工作负载下引起了显著的性能损失。为了充分利用现代硬件提供的低延迟和高带宽优势,存储系统的设计和实现正在进行彻底的革新。
操作系统内核提供的存储和网络堆栈是导致性能下降的一个主要原因。以Linux I/O堆栈为例,其设计主要侧重于可靠性和正确性,同时确保一般用户能够获得可接受的性能。但是,多项研究显示,Linux I/O堆栈在处理高性能硬件时会产生明显的性能损失。这主要是由于其I/O路径冗长、中断和上下文切换频繁所导致的。为了解决这个问题,研究人员开发了一些新的方法,这些方法可以绕过内核存储堆栈,从而充分利用现代硬件的特性。其中,SPDK就是一个典型的例子,它使用用户空间函数调用和轮询机制,而不是系统调用和中断,与硬件进行交互。目前,许多单节点存储系统(如文件系统和键值存储)都是基于这些内核绕过技术开发的,并且在减少I/O延迟方面取得了显著的效果。然而,这些系统的评估主要是在单节点环境下进行的。
随着内核绕过和硬件优化技术在单节点存储堆栈中展现出显著的性能提升,专为现代硬件设计的分布式存储堆栈也开始崭露头角。为了更好地支持现代硬件,许多成熟的存储系统正在进行改进。其中,CephFS是一个分布式文件系统,它最近采用了内核绕过技术,以替代在NVMe和PMem中存储元数据的内核级文件系统。然而,考虑到现有系统在很大程度上是为较慢的存储介质而设计的,因此一些工作已经开始全面重新设计存储堆栈。例如,Intel开发的分布式异步对象存储(DAOS)就是一种先进的存储系统,它完全重新设计了I/O路径,以适应现代硬件的高性能特性。
尽管已经提出了许多分布式存储堆栈来充分利用现代硬件的优势,但这些不同优化技术对各种工作负载性能的影响尚未得到深入评估。目前,许多包含内核绕过技术的存储系统的评估仍局限于单节点环境,而且许多评估仅使用合成工作负载在模拟的硬件上进行。因此,从现有的研究来看,我们尚不清楚为现代硬件重新设计存储堆栈会对实际的分布式科学应用性能产生多大的影响。
本研究旨在量化为现代硬件重新设计存储堆栈对真实模拟和深度学习HPC工作负载性能的具体影响。为此,我们全面评估了DAOS 2.0,这是一种专为现代硬件而构建的先进分布式存储堆栈。我们量化了DAOS的各种软件堆栈优化相对于传统基于内核的方法在现代存储和网络硬件(包括NVMe和PMem)上的性能影响。研究结果表明,在高性能存储硬件上,DAOS在各种合成和真实工作负载下的性能表现优于传统存储系统(如OrangeFS),性能提升幅度高达15倍。
2 背景与相关工作
近年来,人们对于优化存储堆栈的兴趣日益浓厚,旨在最大限度地发挥存储带宽和延迟的潜力。这一努力涵盖了从操作系统级别的变更到设备驱动程序,再到整个分布式存储系统设计的方方面面。为了实现这一目标,各种创新的存储堆栈设计被提出来,并且已经对它们在分布式层面的影响进行了一些研究。
2.1 分布式存储堆栈
虽然已经对单节点存储堆栈的设计进行了许多更改,但这些更改的影响也必须在分布式层面上进行理解。由于单节点I/O堆栈优化的成功,分布式存储堆栈也在不断发展,以优化现代存储硬件的高性能。一些存储系统正在进行修补,以利用这些新接口,同时对其整体设计进行最小的更改,而其他系统则是从头开始开发的。
传统存储堆栈
OrangeFS [4] 和 BeeGFS [9] 是传统的针对高性能计算环境设计的存储系统。OrangeFS从Linux内核4.6版本开始作为附带组件提供,它通过一个用户空间的FUSE插件来执行I/O操作。BeeGFS则配备了一个自定义的内核模块,充当内核级文件系统。在执行I/O操作时,OrangeFS和BeeGFS会数据划分为条带并在存储服务器之间进行分发。条带的位置由元数据服务器管理,该服务器默认情况下与存储服务器共存,以实现可伸缩性。这两个系统目前都使用默认提供的操作系统I/O接口,并且除了RDMA能力之外,并没有专门进行优化以支持高性能的现代硬件。
优化后的存储堆栈
CephFS [5] 是基于Ceph的分布式对象存储RADOS构建的POSIX兼容文件系统。它致力于提供先进、多功能、高可用性和高性能的文件存储,满足各种应用的需求,包括共享主目录、HPC临时空间和分布式工作流共享存储等传统场景。最近,CephFS采用了内核绕过技术[2],例如SPDK [32]和DAX [12],以替代用于存储元数据的内核级文件系统。这种改进带来了内核绕过存储后端的显著性能提升。评估工作主要在一个由RAM和HDD组成的16节点集群上进行,并未在PMem环境下进行评估。另外,还对NVMe进行了一次合成实验。
模块化存储堆栈
近来的研究致力于提供模块化的存储堆栈,以克服操作系统内核带来的软件开销,并针对特定的工作负载和硬件进行定制化。Mochi [30] 提供了多样的构建模块,用户可以灵活组合,迅速构建高度定制的分布式存储系统。LabStor [26] 则推出了一个可扩展的平台,旨在加速开发新型的、硬件优化的、针对特定工作负载的存储堆栈。利用该平台,用户可以开发各种存储模块,包括每节点的I/O调度器和分布式存储系统,并将其组合成高度优化的I/O堆栈。这些研究的评估工作主要在模拟硬件和NVMe环境中进行。
DAOS
分布式异步对象存储(DAOS)[24] 是由英特尔开发的先进存储系统,专为充分利用现代硬件如NVMe和PMem而设计。DAOS要求存在NVMe或PMem以充当元数据的持久缓存。对于NVMe,可以使用SPDK直接与NVMe交互,绕过内核。对于PMem,可以使用DAX将PMem直接映射到DAOS的地址空间,以最小化内核开销。
DAOS具有两个关键存储概念:池(Pool)和容器(Container)。DAOS池是对一组存储节点的存储硬件的抽象,一个池可以包含不同类型的存储硬件,且按存储类型(如NVMevs.PMem)进行分层。系统支持最多几百个池。DAOS容器是一个事务性对象存储,可从DAOS池中分配,代表着不同的存储系统,例如文件系统或键值存储。最多可以有几百个容器,每个容器可以存储数十亿个对象(如文件)。默认情况下,DAOS建议将容器分配的空间的6%分配给PMem/NVMe,而将94%分配给大容量存储(例如HDD),以确保元数据存储在高性能层,而数据操作则存储在速度较慢的高容量层。
DAOS提供多种接口,包括POSIX、MPI-IO、HDF5、Spark和Hadoop,以与容器进行交互。对于POSIX,提供了FUSE文件系统和截获器,可通过LD_PRELOAD加载。文件系统截获器旨在减少FUSE引入的开销。与传统的并行文件系统(如OrangeFS)不同,DAOS存储可变大小的信息块,而不是使用固定大小的分条带,从而避免了对小于条带大小的I/O操作的高延迟访问。
现有基准测试
近期的研究主要聚焦于评估DAOS组件在实际硬件规模上的性能表现。大部分研究主要针对DAOS组件本身进行分析[13],仅将其与自身进行比较。部分研究已经将DAOS与其它存储系统在基于IOR的工作负载下进行了性能对比,例如:IO500 [25]利用IOR和mdtest基准测试生成合成工作负载,以测试存储系统的性能极限。在2019年的10节点挑战中,DAOS获得了相比其他提交的最高分。其他研究采用了类似的方法,使用IOR来比较DAOS和Lustre [28]。尽管这些研究为调整DAOS的最佳方式及确定适用于DAOS的工作负载类型提供了一些启示,但现有的基准测试尚未充分展示DAOS在实际工作负载下的性能影响。
2.2 动机
尽管已经提出了众多存储系统设计变更建议,旨在充分整合现代存储硬件的高性能,但对于这些设计决策如何影响实际现代硬件上运行的真实科学应用的性能,我们仍所知甚少。目前,针对硬件优化存储堆栈的评估主要集中在单节点设置中,完全忽略了网络成本。对于分布式影响的评估,通常是在模拟硬件上进行,或者仅考虑NVMe。最后,现有的评估仅基于合成工作负载(如IOR),而未衡量对实际模拟和深度学习HPC应用程序性能的影响。为了真正了解为现代硬件优化的存储堆栈所带来的性能提升,我们需要在存储系统之间进行评估,使用真实的硬件和应用程序。
3 评估
硬件配置
我们在一个由3个节点组成的集群上进行了所有实验。每个节点配备了512GB内存、8个256GB的Intel Optane DC持久内存和16个4TB的NVMe。此外,每个节点还配备了2个Intel(R) Xeon(R) Gold 6342 CPU @ 2.80GHz,每个节点有48个核心和96个线程,总共有144个核心。集群的网络互连采用了100GbE。
软件环境
在我们的实验中,我们使用了内核版本为4.18的CentOS 8操作系统。我们安装了DAOS 2.1.104-tb、OrangeFS 2.9.8以及BeeGFS 3.7.1。对于基准测试,我们采用了IO500(isc’22分支)和DLIO(commit: 2a5ed47)。我们使用mpich 3.3.2进行了所有实验,每个实验执行了3次并报告了平均值。
实验设置
在每个实验中,我们使用了128个进程来运行工作负载生成器。在每个测试中,我们将应用程序与存储/元数据服务器放置在同一节点上。在每次实验之前都会清除缓存。在所有实验中,我们使用了OrangeFS和BeeGFS的默认配置。对于OrangeFS,我们设置了64KB的条带大小,并使用libaio作为I/O后端。BeeGFS也配置了64KB的条带大小,但根据当前工作负载自动调整I/O线程。我们仅在每个节点上使用了一个NVMe进行测试。更多关于实验设置的详细信息将在每个评估中提供。
3.1 IO500
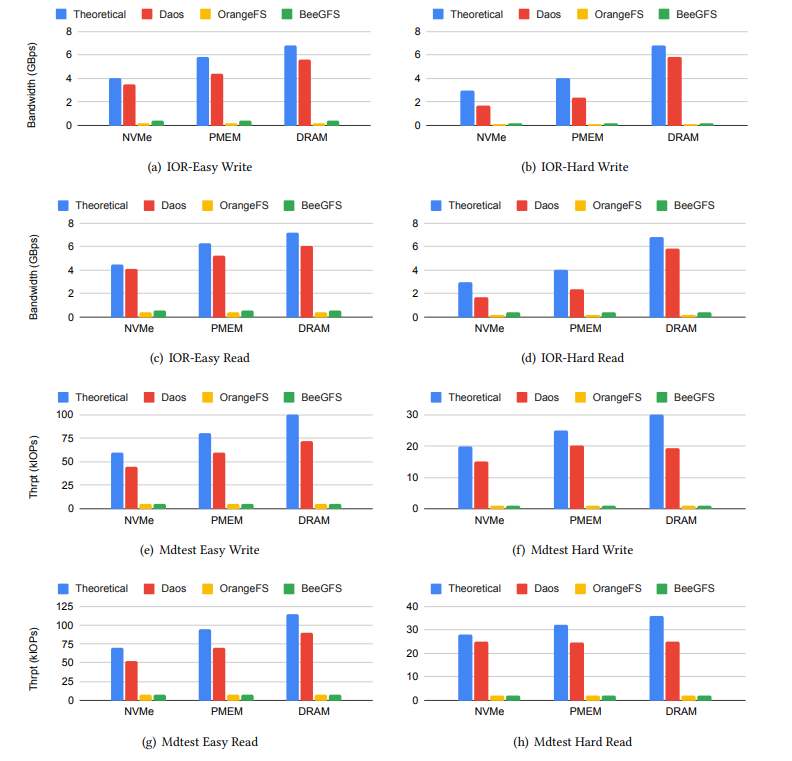
在此评估中,我们对不同的存储堆栈进行了压力测试,以深入了解各系统的基准性能特性。我们采用了IO500[21],这是一种旨在给存储系统施加压力的社区基准测试。我们将DAOS与OrangeFS[4]和BeeGFS[9]进行了比较,后两者是传统的并行文件系统,专为高端计算环境设计。除了支持RDMA网络外,这两个系统均未针对现代存储硬件进行专门的优化。
对于OrangeFS和BeeGFS,我们采用EXT4作为与存储交互的文件系统(在PMem上启用了DAX)。数据以64KB的条带大小进行分布,并以轮询方式在元数据服务器之间进行分配。元数据服务器和数据服务器同时存在。对于DAOS,我们使用SPDK将数据存储在NVMe上,使用DAX将数据存储在PMem上。对于NVMe的情况,DAOS配置为使用50GB的PMem和5TB的NVMe;大多数I/O将针对NVMe而不是PMem。我们对每个测试运行IO500 5分钟。我们测量了IO500执行的各种工作负载的I/O带宽和元数据吞吐量。此外,我们使用dd工具测量了基础硬件的理论带宽和吞吐量,对每个节点的PMem和NVMe设备的设备文件进行了测量。理论带宽的测量不考虑网络影响。
从图1可以观察到,DAOS在不同基准测试中都表现出色。在IO500-Easy实验中,DAOS在NVMe上的带宽比OrangeFS高出10倍,在PMem上高出15倍。IO500-Easy执行的工作负载对于并行文件系统(如OrangeFS)来说是最优的,主要涉及大规模、顺序和对齐的I/O操作。然而,尽管这对OrangeFS是最佳情况,DAOS更为精简的I/O堆栈仍然提供了显著的性能改进。这可能是因为OrangeFS和BeeGFS在处理条带时的元数据管理服务性能。每个I/O被分成64KB的条带,每个都必须在元数据服务器上注册。
IO500-Hard执行了一个不太理想的工作负载,生成小型且不对齐的I/O。在这种情况下,DAOS在NVMe上比BeeGFS和OrangeFS高出8倍,在PMem上高出10倍。性能差异有两个原因。首先,IO500-Hard显著增加了对元数据和小I/O性能的压力,导致由于内核I/O堆栈而产生的开销。其次,BeeGFS和OrangeFS以条带(64KB)的单位执行I/O。对于小于此大小且边界未对齐的I/O,将发生更多的I/O和元数据管理。
对于mdtest-easy和mdtest-hard工作负载,DAOS在NVMe和PMem上至少比OrangeFS快18倍。这是因为DAOS使用了一种用于存储和查询元数据的简洁I/O路径。BeeGFS和OrangeFS都依赖于内核的I/O堆栈。OrangeFS是在EXT4之上运行的FUSE文件系统,而BeeGFS是在EXT4之上运行的内核级文件系统。虽然元数据查询(通常)不直接到磁盘,但它们必须通过多个软件和网络层级以完成,这导致了每个元数据访问的冗长、昂贵的I/O路径。
在合成压力测试的基础上,DAOS所提供的更为精简的软件堆栈在元数据吞吐量、延迟和带宽等各个方面均显著优于传统存储堆栈。尽管这些结果已经表明DAOS在真实应用程序环境下将有良好的表现,但我们还是在一些实际的工作负载中进一步展示了其性能优势。
3.2 机器学习
在此评估中,我们对DAOS与传统存储堆栈在真实深度学习HPC工作负载中的性能影响进行了测量。我们使用DLIO [11]基准测试运行了CosmicTagger [1],这是一个用于区分宇宙像素、背景像素和中微子像素的卷积神经网络。训练数据集包含43万个样本,每个样本包含三个尺寸为1280×2048的图像。样本以稀疏方式存储在HDF5数据集中。在每次迭代中,我们从数据集中读取并预处理32个图像。大多数I/O的大小在20到50KB之间。数据集的总大小为450GB。DAOS配置为具有50GB的PMem和5TB的NVMe。DAOS、OrangeFS和BeeGFS都配置为使用POSIX套接字进行网络操作。DAOS使用SPDK作为其存储后端。OrangeFS和BeeGFS使用EXT4作为其存储后端。
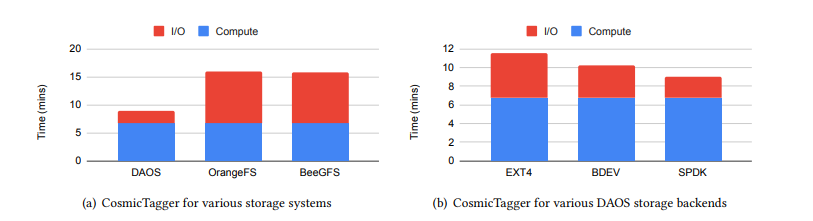
总的来说,我们发现与传统的存储堆栈相比,CosmicTagger在DAOS上的训练速度要快两倍。CosmicTagger的运行时间中,有6.5分钟是用于计算的,涉及到对训练数据的内存样本进行分析。然而,对于OrangeFS和BeeGFS,CosmicTagger在I/O上花费了9分钟。对于DAOS,仅需要2.5分钟。这种性能差异主要有三个原因。首先,DAOS使用SPDK,这比OrangeFS和BeeGFS使用的EXT4文件系统要简单得多。其次,DAOS的设计是围绕着存储硬件的快速认知进行的,因此在关键的I/O路径上尽量减少了软件开销。第三,存储系统在元数据管理、缓存和数据分发策略方面存在差异,这可能导致数据的无谓复制和增加的网络开销。
为了量化这些差异的影响,我们对DAOS的不同配置重新运行了相同的CosmicTagger工作负载。由于DAOS、OrangeFS和BeeGFS之间的网络后端相同,我们主要关注存储后端的影响。我们配置DAOS使用SPDK、Linux块层或EXT4文件系统作为存储后端。
从图2中可以清楚地看到,由于本地存储后端的选择,整体性能存在显著的差异。可以看到,SPDK的性能比Linux内核块层快35%,比EXT4文件系统快55%。已经注意到内核级文件系统和Linux块层会带来一些开销 [26],如内存分配、中断和上下文切换。在使用EXT4时,CosmicTagger在I/O上花费了5分钟,而OrangeFS和BeeGFS花费了9分钟。这解释了传统存储堆栈在这个工作负载中性能损失的大约一半。其余时间是由于处理条带的元数据性能。总的来说,通过使用DAOS提供的I/O堆栈优化,在运行在现代硬件上的真实深度学习工作负载中,可以观察到最多2倍的性能优势。
3.3 模拟
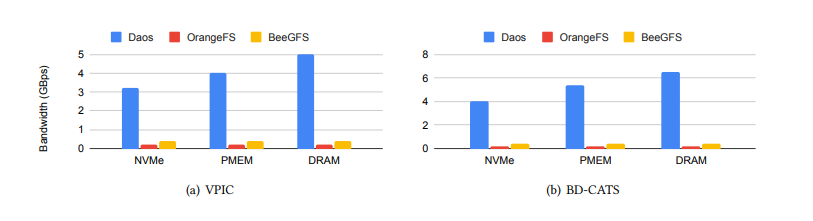
在此评估中,我们量化了优化存储堆栈在HPC中常见的检查点重启模拟工作负载上的好处。为了达到这个目的,我们运行了两个常见的HPC工作负载:VPIC[6]和BD-CATS[29]。VPIC是一个粒子模拟代码,每个进程在每个时间步都会生成粒子数据并将其写入。具体而言,VPIC写入了800万个粒子,每个粒子都是由8个浮点值组成的向量。我们一共运行了16个时间步的VPIC。而BD-CATS则读取由VPIC生成的数据,并执行并行聚类算法。VPIC和BD-CATS主要对HDF5文件进行大规模、对齐的I/O操作,总I/O量达到了500GB。
根据图3展示的结果,无论是使用NVMe还是PMem,DAOS在VPIC和BD-CATS上的运行速度都比OrangeFS和BeeGFS快约6倍。由于VPIC和BD-CATS的计算任务大约只占用了20%的时间,因此性能瓶颈主要出现在I/O方面。I/O性能之所以有大幅提升,主要原因在于BeeGFS和OrangeFS在维护条带时产生了大量的元数据开销,这些条带在读写过程中需要在服务器之间进行分布和查询。总的来说,OrangeFS和BeeGFS执行了800万个元数据操作(每个64KB条带操作一次)。正如IO500的测试结果所示,OrangeFS和BeeGFS的元数据操作大约在5-6 kIOPS的范围内。它们漫长的、基于内核的I/O路径在元数据服务器上引发了显著的软件开销,这就是性能下降的主要原因。总的来说,即使是对于高带宽的HPC工作负载,通过使用硬件优化的存储堆栈也可以获得显著的性能优势。
3.4 讨论
相较于传统的、依赖内核的存储堆栈(如OrangeFS和BeeGFS),DAOS在PMem和先进的NVMes上表现出显著的性能提升。这一优势可以归因于多个因素。
- 首先,DAOS是专门为现代硬件特性设计的,有效减少了关键I/O和元数据路径上的软件开销。
- 其次,通过采用硬件特定的I/O接口(例如SPDK、DAX),DAOS避免了内核堆栈的开销和不必要的数据复制,从而加速了元数据和小型I/O操作,对带宽敏感的工作负载产生显著性能影响。
- 此外,性能还受到元数据管理、数据放置和缓存方面的差异的影响。举例来说,DAOS不依赖于操作系统进行缓存,而是提供了专用的缓存,支持PMem,扩大了缓存容量并减少了数据复制。
这使得DAOS更适合深度学习I/O工作负载的访问特性,从而在元数据成本和软件开销减少的情况下提供显著的性能优势。
然而,尽管DAOS在小规模集群中配备先进硬件时表现出色,但这些评估并未必反映在规模扩大至数千个节点、存储硬件更加多样化的情况下的实际表现。随着规模的扩大,网络拓扑和网络速度可能更为关键,导致DAOS与传统存储堆栈之间的性能差距可能减小。此外,许多集群将HDD作为主要的数据存储介质,而只使用NVMe和PMem作为数据的中间缓冲。我们的评估基于数据集完全适应于NVMe和PMem,未考虑跨PMem、NVMe和HDD的存储层的复杂性。如果数据集主要存储在HDD上,那么改进的元数据性能和减少的软件开销的影响可能会显著降低。对于主要基于DRAM和HDD的传统集群,DAOS和传统存储堆栈的性能可能更为相似。
4 结论
在本研究中,我们对重新设计的分布式存储系统以适应现代硬件的高性能和低延迟进行了详尽的评估。我们通过对比一种先进的存储系统(DAOS)和传统存储系统(OrangeFS + BeeGFS)在各种工作负载以及持久内存和NVMe上的性能进行了全面的基准测试。我们对DAOS中引入的软件堆栈优化在深度学习和仿真工作负载整体性能上的影响进行了量化。通过采用SPDK,我们观察到了高达55%的性能提升,主要得益于小型I/O性能的改善。此外,在查询数据条带的元数据管理性能方面,我们发现在大型和小型I/O操作期间存在显著的性能差异,这导致了仿真和深度学习工作负载性能的显著提升,最高可达6倍。总体而言,我们的研究展示了通过采用专门为现代存储硬件优化的存储堆栈,真实的深度学习和HPC工作负载可以实现高达6倍的性能提升。