随着人工智能和机器学习(AI/ML)解决方案的兴起,我们发现它们具有超越传统企业IT思维的独特基础设施需求。然而,在制定部署计划时,这些独特需求常常被忽略。本文的目的在于分享我们在与一些新兴解决方案合作过程中所积累的经验和知识,以便更清晰地了解这些需求。
HPC技术迈向企业领域
随着AI/ML解决方案在企业中崭露头角,我们的许多客户发现传统的存储系统和文件系统可能无法满足与新的AI/ML工作负载相关的新需求。
最初,NVIDIA与传统的存储供应商合作创建了AI/ML的参考架构。这些参考架构相对较小,包括2-4个DGX1系统和一个或两个存储系统。当时,这些参考架构在实际操作中非常合理,使得大多数企业能够轻松踏上AI/ML解决方案的征程,而不受太多障碍。
然而,随着更强大的DGX2以及随后的DGX A100系统的推出,以及客户希望扩展他们的工作负载,他们发现传统的文件系统和存储系统在某些AI/ML工作负载中缺乏足够的可扩展性和性能。
在高性能计算(HPC)领域,多年来他们已经吸取了这个教训。他们没有采用传统的文件系统或存储系统,而是使用像GPFS、Lustre等并行文件系统。不幸的是,利用这些HPC技术非常困难和复杂,存在着技能和知识差距,以及陡峭的学习曲线来克服这些障碍。
这就是供应商如DDN、IBM和HPE(Cray)可以提供帮助的地方。他们创建了一个“设备”或存储系统,隐藏了GPFS和Lustre的许多复杂性。
DDN已经在HPC市场上经验丰富,他们出色地创建了一个设备,将Lustre文件系统的复杂性隐藏起来。他们推出了专门用于AI/ML的平台,称为A3I平台。这个设备可以非常小,只占用2个机架单元的空间,但容量可扩展到数十PB。DDN是首批支持NVIDIA DGX SuperPOD参考架构的供应商之一,同时也是首批支持NVIDIA GPUDirect存储功能的厂商之一。我们有机会在我们的高级技术中心(ATC)中使用DDN A3I平台。
IBM和HPE(Cray)一直在HPC领域担当市场领导者。IBM通过其Spectrum Scale产品提供GPFS解决方案。现在,IBM Spectrum Scale已成为NVIDIA DGX SuperPOD参考架构的一部分,并支持GPUDirect功能。
HPE提供GPFS和Lustre解决方案,同时还在NVIDIA DGX生态系统之外提供自己的AI/ML参考架构。
这些HPC存储设备在隐藏许多复杂性方面表现出色,但并没有完全消除它。数据网络的安装和配置可能非常复杂。此外,客户端配置也具有一定的复杂性。例如,Lustre在客户端提供了许多配置选项,需要用户了解。
崭露头角的机会,新的参与者
AI/ML解决方案已经变得非常热门。似乎每个企业都制定了战略计划,旨在利用这些解决方案来实现业务目标。通常情况下,随着新技术的涌现,也会带来新的机会。这些新机遇催生了一批新参与者,如WEKA、VAST、Panasas、Pavilion、NGD和Fungible等。
我们有机会在我们的高级技术中心(ATC)中测试和使用WEKA、VAST和Panasas。
WEKA和Panasas定位自己为面向AI/ML的现代平台。它们都采用了自己的并行文件系统,旨在比传统的并行文件系统(如GPFS或Lustre)更好地满足AI/ML工作负载的需求。WEKA表示,传统的并行文件系统是为传统HPC工作负载中的大型IO高吞吐量而设计的,而且已经存在了几十年。传统的并行文件系统还采用了集中式元数据服务器,这可能会成为性能瓶颈。而WEKA专门为AI/ML工作负载设计,这些工作负载可能涵盖较小的IO操作和大型IO操作,它旨在在处理大型和小型IO操作时表现出色。此外,WEKA还具备分布式元数据功能,从而消除了元数据服务器的性能瓶颈。
WEKA是一种SDS(软件定义存储)解决方案,因此可以在合适的服务器平台上运行。HPE提供了一种基于DL服务器的合格参考架构。在我们的ATC中,我们使用了HPE DL325服务器部署了WEKA系统。每个服务器都搭载了19个NVMe SSD,以1U机架的形式提供,这是一种非常密集且性能卓越的解决方案,但价格不菲。不过,值得一提的是,WEKA具备添加对象存储作为第二层存储以降低每TB成本的能力。SDS提供了选择服务器平台的灵活性,但灵活性往往需要用户来实施和集成系统。尽管WEKA的文档非常有用,但我们仍然发现这一过程相当复杂。因此,我们强烈建议使用WEKA的实施服务。
最近,Hitachi还开始将WEKA作为其HCSF(Hitachi Content Software for File)系统的一部分提供。该产品捆绑了服务器、网络和对象存储,以形成一体化解决方案,并在机架中进行了预安装和配置。这极大地简化了系统的实施过程,并提高了实施速度。
VAST主要使用NFS作为主要访问协议,但他们对其进行了一些技术改进。他们利用了NVMeoF技术,搭配SCM、QLC SSD和高速的100/200G网络。除了这些先进的硬件技术外,他们还通过使用RDMA/TCP的多路径NFS协议对NFS进行了增强。根据VAST的说法,这种增强使他们的性能达到了普通NFS的80倍(160GB/s)。
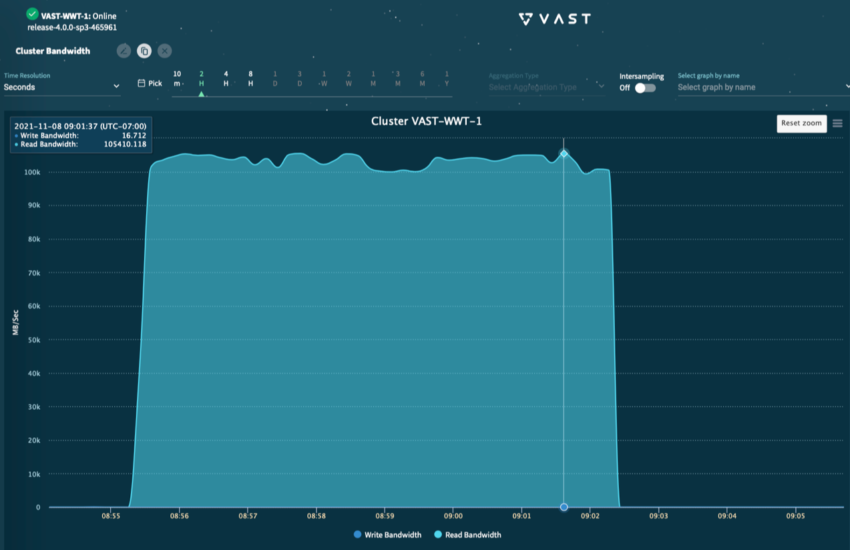
我们在ATC中使用的VAST系统是一个3×3系统,包括3个服务器机箱、3个数据机箱和两个Mellanox SN2700交换机。通过将我们的系统连接到单个DGX A100系统,我们能够实现超过100GB/s的性能。
虽然WEKA和Panasas都提供了常规的NFS客户端访问方式,但为了获得最佳性能,它们建议使用其专有的客户端。然而,这些客户端的安装、配置和优化可能会相当复杂。WEKA和VAST是首批支持NVIDIA DGX SuperPOD参考架构的供应商之一,也是首批支持NVIDIA GPUDirect Storage功能的供应商之一。值得注意的是,GPUDirect Storage功能需要使用其专有客户端。
不要忽视新的数据网络
除了新的文件系统,新的AI/ML解决方案还需要更快速的网络连接。许多NVIDIA DGX SuperPOD参考架构都采用InfiniBand和/或100/200G以太网。在传统的HPC环境中,InfiniBand一直是标配连接方式已经多年。然而,大多数企业对InfiniBand并不熟悉。他们更倾向于以太网,但100G/200G以太网与企业中常见的以太网有所不同,尤其是带有RoCE的100G/200G以太网。新数据网络的配置也是一个充满复杂性和技能差距的领域。
我们注意到,大多数NVIDIA SuperPOD参考架构都采用了InfiniBand。在我们的实验室中,我们在WEKA集群中采用了InfiniBand。由于我们的WEKA集群规模较小,所以我们只需要一个单独的InfiniBand交换机,而且配置它并不太复杂。幸运的是,WEKA提供了相当好的文档,因此即使没有之前的InfiniBand经验,我们也能够使其正常运行。不过,如果我们需要一个需要多个InfiniBand交换机的较大集群,可能会面临更多挑战。
在我们的测试期间,NVIDIA已经将RoCE作为支持GPUDirect Storage配置的选项,但我们并没有找到相关的参考实施案例。我们与VAST合作,尝试使用RoCE来实现GPUDirect Storage。虽然最终我们成功了,但需要花费很多小时来正确实施。最大的难点在于配置数据网络,这一过程复杂度来自于我们的配置中有多个交换机。我们使用了VAST系统附带的2个SN2700交换机,以及我们自己DGX A100系统上的1个SN3700交换机。连接和正确配置网络比我们预期的复杂多了。