摘要
高性能的可扩展存储系统在现代HPC和AI集群中具有关键地位。然而,对其性能进行准确的表征仍然具有一定挑战,因为不同的客户端I/O模式呈现出高度不同的性能扩展行为,而HPC存储软件中的瓶颈也可能限制了性能的扩展。分布式异步对象存储(DAOS,Distributed Asynchronous Object Storage)是一个开源的可扩展存储系统,从根本上设计用于在用户空间支持SCM和NVMe存储。DAOS在IO500基准测试中展现出领先的性能。然而,尽管IO500已经定义了一组广泛的“标准”I/O模式,但单个IO500运行并不能深入了解存储解决方案的扩展性。
本文通过研究DAOS存储栈在典型的IOR和mdtest工作负载下随着存储服务器硬件和客户端并行性能的扩展行为,来探讨DAOS存储性能的扩展性。同时,本文还分析了高性能计算网络栈(libfabric/verbs和UCX)对可实现性能的影响,以期为DAOS存储性能的优化提供有益的洞察。
引言
几十年来,超算的存储解决方案一直主要关注于容量和顺序带宽的优化,这导致计算科学家必须将复杂的应用程序级访问模式映射到多层存储软件栈中的存储硬件 [1]。因此,I/O密集型应用程序通常只能实现存储系统峰值性能的一小部分。为了更好地理解在多样化的工作负载下存储系统的行为,IO500基准套件 [2, 3] 引入了一组扩展的综合存储性能基准。然而,单个IO500基准运行无法为决定存储解决方案整体性能的参数提供足够的洞察:
- 给定基准的性能是否随着存储系统数量的增加成比例增加?或者性能受到存储软件中的瓶颈限制,从而无法充分利用底层存储硬件的原始性能?
- 当基准在某一数量的客户端节点上运行时,是否已经使存储系统达到饱和状态?或者在添加更多客户端节点(以及/或增加每个客户端节点的任务数)时,性能是否能够进一步扩展?
- 随着每个客户端节点的任务(或线程)数量的增加,基准的性能如何变化?是逐渐增加并趋于稳定,还是受到存储软件(或网络栈)中的限制,在高任务数节点上性能会下降?
尽管对于大型顺序I/O模式,这些问题的答案可能相对明确,但对于较小的I/O大小或元数据中心的工作负载来说,答案却远不那么明确。
本研究的目标是对DAOS存储栈的扩展行为进行深入分析,涉及上述问题。DAOS系统架构如图1所示。DAOS从头开始设计,以利用现代化存储硬件(SCM、NVMe和CXL SSD)。其先进的低级键值API使其具有比传统基于POSIX的并行文件系统更高的IOPS和可扩展性,DAOS的IO500结果 [2] 也证实了这一点。需要注意的是,虽然DAOS提供了POSIX抽象层,但它也可以直接与自定义I/O中间件(如MPI-IO、HDF和几个AI/分析框架)集成,以提供比POSIX更多的功能。本研究仅在DAOS POSIX容器之上使用DAOS DFS API。
我们使用与IO500类似的合成基准,并通过变化客户端资源、服务器资源、网络栈和DAOS提供的用户可控数据保护方案来重复每个基准。得到的扩展图将比单个特定系统配置的点测量结果更好地理解性能行为。
本研究的结果可用于多种方式:在采购时,解决方案架构师可以基于最能代表客户需求的基准的扩展特性来确定DAOS存储解决方案的大小。存储管理员可以使用结果验证操作环境的健康状况,例如识别不良硬件或软件更新后的性能退化。如果发现了扩展限制,这可以指导DAOS软件开发人员对开源DAOS软件栈进行未来的代码优化。
高性能计算存储性能指标
本节描述了本文研究的性能指标。
带宽和IOR基准测试
IOR基准测试工具[7]是HPC存储解决方案带宽测量的事实标准。IOR支持许多后端驱动程序,可以通过IOR API的(-a)选项进行选择。默认的API是POSIX。本研究中的所有运行均使用IOR的API=DFS后端,该后端使用DAOS文件系统(DFS)API直接执行I/O,将数据直接写入DAOS POSIX容器[8]。
在将filePerProcess(-F)选项设置为零的情况下,IOR将使用一个共享文件,所有客户端任务将同时访问该文件。相反,将filePerProcess设置为1将为每个MPI任务创建一个文件。这种模式可以在不能很好处理并发访问的存储系统上提供更好的性能。但是处理大量文件可能会引发其它问题。我们的基准测试已经证实,在使用单个共享文件或每个进程使用一个文件的情况下,DAOS的带宽几乎是相同的。本研究中的所有运行均使用filePerProcess=0(通常是可实现带宽较低的模式)。
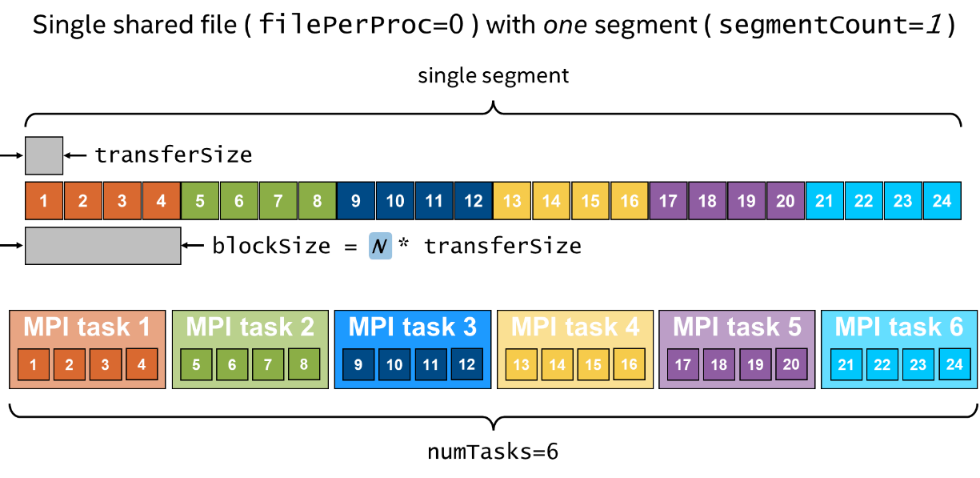
IOR基准测试工具的第二个重要参数化是文件访问模式。图2显示了单个大文件的“块”(顺序)布局,在此布局中,每个MPI任务访问文件中的连续字节范围。在IOR术语中,此文件使用segmentCount(-s)为1,且blockSize(-b)是transferSize(-t)的整数倍。此模式对于大型顺序访问是典型的,例如流式传输大型检查点文件、图像或视频。在IO500中,这是“IOR-Easy”情况,因为使用此I/O模式通常很容易达到HPC文件系统的理论峰值带宽。(IO500规则还允许在“IOR-Easy”情况下使用filePerProcess=1,这对于某些其它并行文件系统有所帮助,但对于DAOS来说不是必需的。)
需要注意的是,执行客户端缓存或缓冲的文件系统可以在使用此文件访问模式时实现良好的性能,即使transferSize很小。客户端可以将应用程序的多个小连续I/O请求聚合起来,然后以较大的块对存储系统执行I/O。通过这种技术,即使是基于磁盘的并行文件系统在进行小的应用程序传输时也可以表现得相当不错。DAOS DFS API不执行任何客户端缓存。但是,DAOS是一种全闪存存储系统,NVMe SSD应该可以在无缓存的情况下达到其峰值带宽。在具有足够多客户端任务的情况下,DAOS存储系统的峰值硬件带宽应该可以在小的transferSize下达到,无需任何客户端缓存。这将在第5节进行研究。
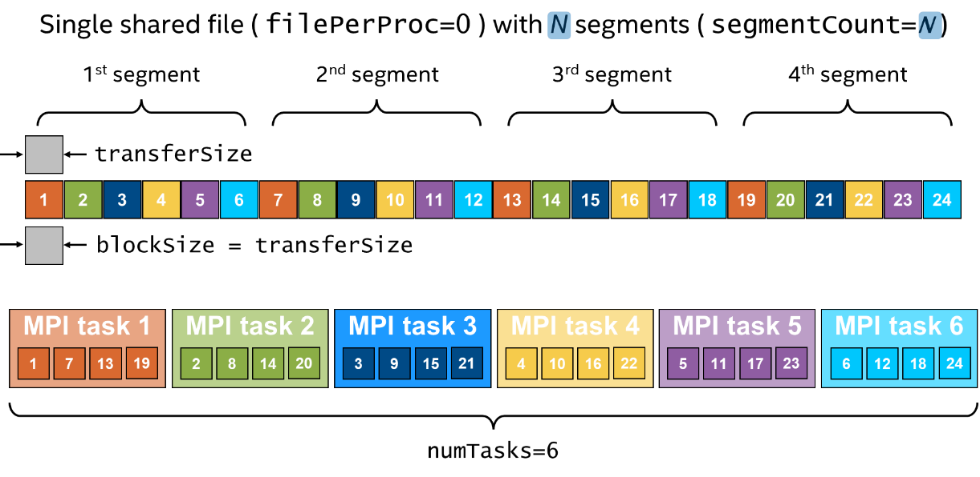
图3显示了单个大文件的“循环”(跨距)布局,这在科学应用中很常见,每个MPI任务都在访问大文件的许多不连续的部分(例如,多维数组的部分)。在IOR术语中,此文件由许多段组成,对于每个段,每个客户端任务都会进行一次传输,因此IOR blockSize(-b)与transferSize(-t)相同。
这种访问模式可能会导致并行文件系统的性能问题,这些文件系统依赖于锁定或访问令牌来保证并行访问的一致性。因为单个MPI任务访问文件内的许多不连续字节范围,所以一致性机制所产生的开销可能会导致严重的性能降低。IO500的“IOR-Hard”测试用例已经设计出现这种问题:它使用循环数据分布,传输大小为47008字节,这个大小选择也会导致未对齐到页面或文件系统块边界的I/O请求。DAOS使用其版本化对象存储(VOS)[4]来确保一致性,无需字节范围锁定或令牌。本研究的重点之一是研究“循环”或“跨距”访问模式的DAOS带宽如何接近顺序I/O的“最佳情况”带宽。
元数据速率与mdtest
为了衡量文件系统元数据操作的性能,可以使用mdtest工具。与IOR类似,它为DAOS POSIX容器(API=DFS)提供了DAOS后端,并且可以配置为表示许多不同的以元数据为重点的工作负载。本研究使用了在IO500基准套件[2]中标准化的一组元数据测试:
- mdtest-easy:对0字节文件执行元数据操作,为每个MPI任务使用单独的目录(mdtest -u)。特别地,测量了文件的创建、状态查询和删除操作。
- mdtest-hard:在共享目录中对小文件执行元数据操作。此测试测量了单个大目录中大小为3901字节的文件的创建+写入、状态查询、读取和删除操作。
可实现的元数据性能严重依赖于存储解决方案软件实现的细节,而对于个别存储设备或块存储控制器的“随机4 KiB IOPS”数字与存储解决方案能够执行这些更为复杂的文件系统级操作的速率没有直接关系。由于这些固有的软件限制,通常不清楚额外的元数据功能硬件是否会在多并行文件系统的元数据性能方面带来改进。
DAOS数据模型承诺消除或至少大大减少传统并行文件系统中存在的元数据性能瓶颈。DAOS将其元数据和小写入(<4 KiB)存储在SCM中,并且元数据完全分布在所有DAOS服务器上。这与像Lustre [9]或BeeGFS [10]这样的并行文件系统不同,后者通常受限于少数专用的元数据服务器。GPFS [11]并行文件系统可以配置为完全分布式的元数据,特别是在其GPFS本地RAID(GNR)形式[12]中。GPFS的内部一致性机制传统上是导致像IO500“IOR-Hard”测试案例这样的访问模式带宽较低的原因,但最近已经有所改进[13]。
本研究的一个重要目标不仅是测量典型DAOS服务器配置的绝对元数据速率,更重要的是提供一些见解,即这些元数据速率如何随着服务器硬件资源数量和客户端进程数量的增加而扩展,以验证是否存在会阻止扩展的软件瓶颈(在服务器端或客户端端)。
基准测试环境
本节简要描述了本研究所使用的基准测试环境。所有运行均在生产HPC集群上进行,具有对四台DAOS存储服务器的专用访问权限,但与存储基准测试并行在集群上进行通用用户操作。
硬件配置
采用了以下硬件配置:
最多4个DAOS服务器节点。每个服务器包括:
- 2颗Intel IceLake 8352Y CPU(每个插槽32核心,2.2 GHz)
- 16颗DDR5 16 GiB DRAM DIMMs(总共256 GiB)
- 16颗Intel Optane Persistent Memory 200 Series 128 GiB DIMMs(总共2 TiB)
- 8颗Intel /Solidigm D7-P5500 3.84 TB PCIe gen4 NVMe SSD(总共30 TB,有关性能规格,请参见[14])
- 2颗单端口NVIDIA ConnectX-6 HDR200 InfiniBand网卡
最多48个客户端节点。每个客户端包括:
- 2颗Intel IceLake 8352Y CPU(每个插槽32核心,2.2 GHz)
- 16颗DDR5 16 GiB DRAM DIMMs(总共256 GiB)
- 1颗单端口NVIDIA ConnectX-6 HDR200 InfiniBand网卡
具有NVIDIA QM8790 HDR交换机(2级Clos拓扑)的完全非阻塞InfiniBand HDR互连结构。
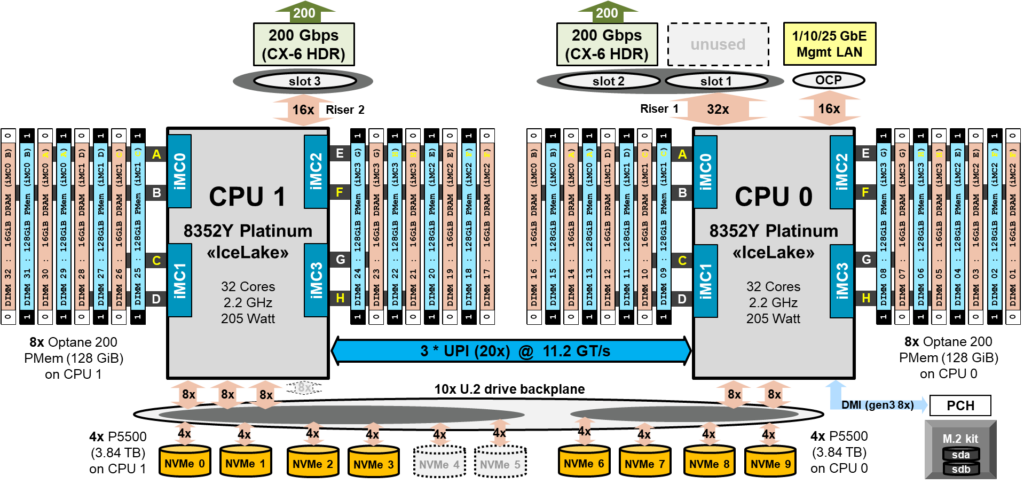
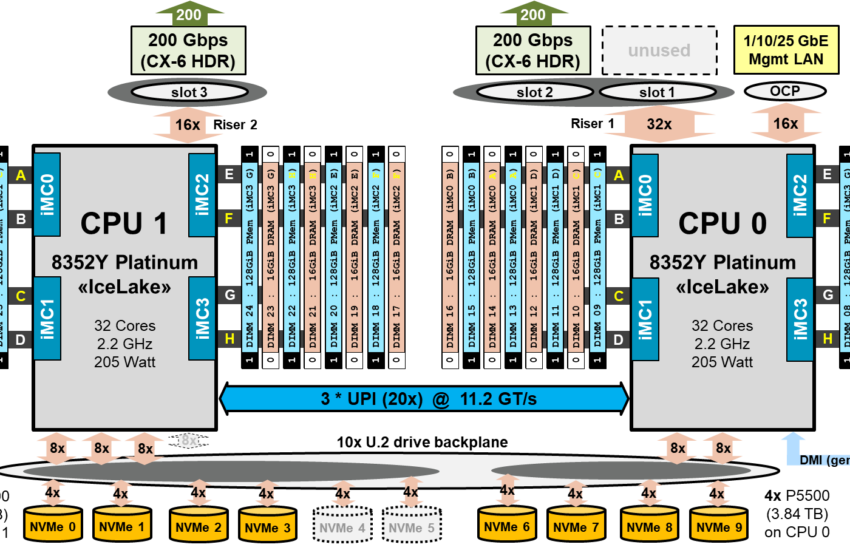
DAOS服务器不使用超线程。在DAOS客户端上,超线程已启用,但未使用(仅在48个节点和每个节点128个MPI任务的少数运行中使用,以验证更高总MPI任务数下的扩展性)。需要注意的是,DAOS每个物理CPU启动一个daos_engine进程,该进程管理与该CPU本地相关的硬件资源,以避免任何NUMA效应。因此,在结果部分引用的“引擎”包括两个服务器CPU中的一个,八个PMem DIMM,四个NVMe SSD和一个单个HDR网络链路,即完整DAOS服务器硬件资源的一半。图4显示了本研究中使用的DAOS服务器的系统块图。
软件环境
本研究使用了以下相同的软件环境(在服务器和客户端上相同):
- CentOS Linux 8.4.2105 版本
- MLNX_OFED_LINUX-5.6-2.0.9.0,包括ucx-ib-1.13.01.56209.x86_64
- DAOS v2.3.101-tb(用于DAOS v2.4版本的首个测试构建),包括libfabric-1.15.1-3.el8.x86_64和mercuryucx-2.2.0-3.el8.x86_64
- MPICH 3.4.2,带有GCC 9.4.0
- DAOS服务器已根据DAOS文档[16]中的最佳实践建议进行了配置。在元数据基准测试期间,已变化的主要参数是每个DAOS引擎的存储目标数量(在/etc/daos/daos_server.yml的engines部分中的targets设置)和网络堆栈(DAOS服务器配置文件中的provider设置)。每个目标需要一个物理CPU核心,因此每个引擎的目标上限是一个CPU插槽的核心数。
基准测试方法
本研究中的所有基准测试均已重复三次,并报告的数据是这三次迭代的平均值。IOR基准测试的写入阶段使用60秒的保障时间。对于具有远高于写入带宽的读取带宽的NVMe SSD的硬件配置,读取阶段通常持续30至60秒。由于DAOS DFS API不执行任何缓存,此运行时足以达到稳态并获得稳定的结果。mdtest基准测试的写入阶段使用30秒的保障时间。
客户端扩展性
通过在不同数量的客户端节点上执行所有基准测试,并在每个客户端节点上执行不同数量的MPI任务,对客户端扩展性进行了分析。从一个客户端节点到48个节点的运行已经完成,并且对于每个节点计数,每个节点的MPI任务数量从1变化到64(在某些情况下为128,以获得启用超线程时的额外扩展性数据点)。
本研究中的所有扩展性图表都在x轴上显示基准测试的总MPI任务数量(对数刻度),给定节点数的不同任务数以相同颜色的线图显示。
服务器端扩展性
对于带宽,已研究了五个不同的问题:
- 单个DAOS引擎的HDR InfiniBand链路带宽为200 GB/s,需要多少个NVMe SSD才能饱和?第5.1节中对此进行了讨论。
- 对于给定的DAOS服务器配置,可实现的带宽如何依赖于应用程序传输大小?大型(1 MiB)和小型(64 kiB)传输的结果在第5.2节中显示。
- 图3中的IOR“循环”I/O模式(用于IO500“IOR-Hard”基准测试)的带宽与图2中的顺序IOR“块”I/O模式的带宽相比如何?这在第5.3节中研究。
- 选择DAOS对象类(用于数据保护)对带宽有何影响?典型的对象类在第5.4节中进行了测量。
- 带宽如何随着DAOS引擎的数量增加而扩展(一个DAOS服务器运行两个DAOS引擎)?第5.2节至第5.4节中的研究已在一个引擎(DAOS服务器的一半)到8个引擎上进行。
所有带宽测试均使用每个DAOS引擎固定数量的16个存储目标(CPU核心)进行,因为其它实验(未在此处显示)已确认带宽结果不会明显依赖于存储目标数量。
相反,元数据基准测试首先关注的是服务器CPU资源数量如何影响元数据速率,对于存储设备的固定配置(每个存储引擎的八个PMem DIMMs和四个NVMe SSD)。这与为了实现最佳性价比在DAOS存储服务器中进行CPU大小选择有关,第6.1节证明元数据速率确实随着CPU核心数量的增加而增加。
为了分析元数据性能如何随存储设备数量扩展,已进行了一系列具有不同数量的DAOS存储引擎的扩展性测试。这些测试使用了每个引擎16个存储目标,以限制参数空间。第6.2节报告了多达四台DAOS服务器(八个DAOS引擎)的扩展性结果。
网络堆栈的性能影响
对于所有高性能分布式存储解决方案,HPC互连在其中起到至关重要的作用,通常首选具有RDMA功能的互连。DAOS 2.0及更早版本依赖于libfabric [17]和mercury [18]作为其网络层。在InfiniBand互连(或具有RoCE的以太网互连)中,libfabric/verbs提供了RDMA功能。从版本2.2开始,DAOS还支持UCX [19]在InfiniBand互连上,作为libfabric/verbs的替代方案,mercury在UCX之上为DAOS提供了更高级别的网络功能。
存储系统的元数据性能受到HPC互连处理大量小型RPC的能力的影响。为了分析网络堆栈对可实现性能的影响,存储服务器已配置为同时使用libfabric/verbs和ucx+dc_x提供者,以比较所得的元数据速率。下面的第6节中将并列显示这两个提供者的结果。
数据保护对性能的影响
在传统的HPC存储系统中,系统管理员会为HPC存储配置特定的数据保护方案,例如无数据保护的分区(RAID0)、镜像(RAID1)或N路复制,RAID5、RAID6或其它纠删码方案。终端用户无法对选择的数据保护方案进行控制,而站点提供的内容可能与其应用程序的I/O模式是否匹配不上。
在DAOS中,为用户/组/项目(在DAOS池中)分配原始存储容量的管理任务与用户如何使用该原始存储容量的细节分开。数据在该池中的结构(由DAOS容器的类型表示,例如DFS表示POSIX容器)以及容器中对象的数据保护级别由最终用户确定。为了方便起见,DAOS池级别上设置了一些默认属性(如果在创建容器时未指定这些属性的值,它们将传播到在该池中创建的容器),但通常用户可以在容器级别甚至每个单独对象级别指定属性,例如数据保护方案。这是一个巨大的优势:DFS(POSIX)容器中的文件和目录的DAOS对象类别可以根据用户对I/O模式的了解而显式选择。
IOR和mdtest基准测试的DFS后端允许用户选择目录和文件的DAOS对象类别,这对于不同数据保护方案的性能基准测试非常方便。在IO500基准测试套件的配置文件中,可以为每个IO500基准测试指定这些对象类别,同时API=DAOS(这些设置仅在写入阶段中相关)。
注:EC条带的宽度不能大于存储池中的服务器数量(例如,EC_8P2GX至少需要10个DAOS服务器)
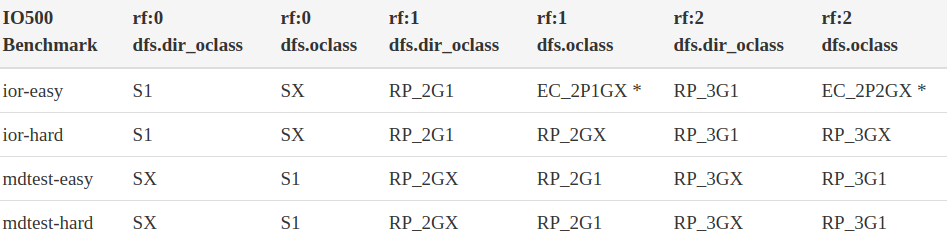
表1显示了在本研究中使用的目录和文件对象类别的最佳实践设置。对象类别的助记名编码了两种类型的信息:
- 数据保护方案:分片/条带化(S*)、N路复制(RP_)或纠删码(EC_)。可以选择EC条带的宽度,并且可以使用每个完整条带的2、4、8或16个数据条的方案。
- 数据放置方案:S1表示对象完全放置在单个存储目标上,而SX表示对象分布在池中所有可用的存储目标上。与N路复制和纠删码方案一起使用的G1和GX类别也适用相同的逻辑。
表标题中的冗余因子指定了更高级别所需的容错级别:这里,rf:0表示不需要容错,rf:1表示对象可以经受住单个故障,rf:2表示对象可以经受住两个独立故障(DAOS支持最多rf:5)。对于为DAOS容器配置的给定冗余因子,尝试使用较低容错级别创建对象将导致I/O错误。在具有较低容错级别的容器中创建具有更高容错级别的对象是受支持的。
对于只创建一个文件的IOR基准测试,将目录条带化到多个目标上没有好处,因此对于目录来说,S1或G1是最佳选择。另一方面,mdtest基准测试会创建数十亿个文件,因此在mdtest基准测试的目录中使用SX或GX对象类别非常有益。
IOR创建一个巨大的文件,为了获得最佳性能,此文件需要跨足够多的存储目标进行条带化。因此,GX是IOR测试文件的自然选择。IOR-Easy的大型顺序访问模式与纠删码相配,而IOR-Hard的小型非对齐I/O请求更适用于复制对象。mdtest创建的文件要么为空(用于mdtest-easy),要么大小为3901字节(用于mdtest-hard)。这意味着对于mdtest来说,S1是文件对象类型的最佳选择以避免开销(或者在需要复制时使用G1)。
带宽结果
本节研究了DAOS带宽在四个不同领域的扩展性:
在第5.1节中,对每个DAOS存储引擎中的NVMe SSD数量进行了变化,以指导针对读取或读写导向工作负载的DAOS解决方案配置。
第5.2节研究了“IOR-Easy”顺序带宽扩展性如何受到应用传输大小的影响,研究了单个DAOS服务器和一个没有数据保护的四个DAOS服务器的集群。
在第5.3节中,我们报告了“IOR-Hard”的结果,这对于传统的并行文件系统来说通常表现得非常糟糕。“IOR-Hard”基准测试的目标是双重的:首先,展示DAOS可以实现与“IOR-Easy”(具有“循环”数据分布)相当的“IOR-Hard”带宽。其次,我们的目标是验证“IOR-Hard”带宽是否随着DAOS存储服务器数量的增加而扩展(以验证存储栈中是否存在软件瓶颈,阻止有效利用额外的存储硬件)。
最后,第5.4节研究了数据保护(DAOS对象类别)对IOR-Easy和IOR-Hard工作负载的影响。
每个引擎的NVMe SSD数量与带宽扩展
存储解决方案的峰值总带宽由其原始存储设备的总带宽确定,受网络带宽以及任何潜在的软件开销限制。至少对于简单的顺序访问模式,性能应该与可用的硬件资源成线性扩展。
每个DAOS存储引擎使用单个高速网络端口。在本研究中,使用了单个200 Gbps的HDR InfiniBand连接,其峰值带宽为25.0 GB/s = 23.28 GiB/s。MPI级的点对点带宽测试,如ib_write_bw和ib_read_bw,可以实现接近23 GiB/s的带宽(至少在消息大小为64 kiB或更大时)。由于单个客户端进程通常无法用存储流量饱和200 Gbps的网络连接,因此预期每个客户端任务的带宽会随着客户端任务数的增加而有所变化。
DAOS存储解决方案的一个重要设计考虑因素是每个DAOS存储引擎应该配置多少个NVMe SSD。通常,目标是完全饱和引擎的网络连接。本研究中使用的NVMe SSD是Intel/Solidigm D7-P5500 3.84TB SSD [14]。其产品规格列出了以下性能特性:
- 顺序读取带宽:7000 MB/s = 6.52 GiB/s
- 顺序写入带宽:3500 MB/s = 3.26 GiB/s
- 随机4 kiB读取:780000 IOPS * 4 kiB = 2.98 GiB/s
- 随机4 kiB写入:118000 IOPS * 4 kiB = 0.45 GiB/s
尽管存在读写带宽非常相似的NVMe SSD,但在这里使用的NVMe SSD在其写入带宽显著低于读取带宽方面非常典型。这引发了一个问题,即服务器是否应该针对读取导向的工作负载(如AI训练)进行优化,或者是否应该同时优化写入带宽。
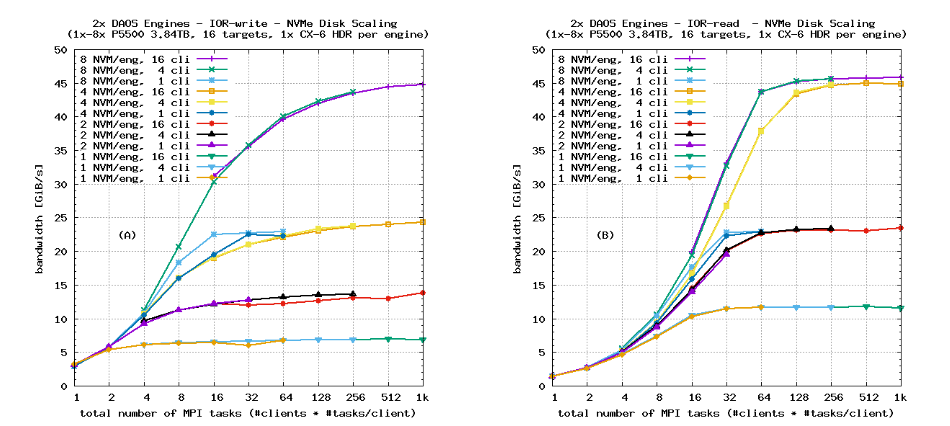
图5显示了单个服务器的写入带宽和读取带宽,作为每个引擎的P5500 NVMe SSD数量的函数。与本节中所有带宽图表一样,左图显示写入带宽,右图显示读取带宽。与规格表性能数据一致,服务器的总写入带宽在每个引擎有八个NVMe SSD的情况下增加,而读取带宽在每个引擎有四个NVMe SSD的情况下已经达到峰值。
本研究中使用的存储系统针对读取导向的工作负载进行了优化,因此在本文的其余部分中,所有配置都使用四个P5500 NVMe SSD。每个引擎的峰值带宽大致为13 GiB/s(受磁盘限制)和23 GiB/s(受网络限制)。理想情况下,这些极限应该适用于小至20 kiB的传输大小;对于小于20 kiB的RPC大小,DAOS将不使用RDMA,因此性能特性将有所不同。对于非常小的传输大小,NVMe带宽和HDR带宽也会较低。
应用传输大小的带宽扩展
图6显示了使用顺序IOR“块”布局和SX对象类别(无数据保护)对单个服务器进行的顺序带宽测试结果。明显可见峰值服务器带宽以及客户端网络限制。图7重复了同样的基准测试,针对具有四个服务器的DAOS系统,再次展示了完美的扩展性。这是预期的,因为许多HPC存储解决方案在顺序I/O工作负载下表现出良好的扩展性。
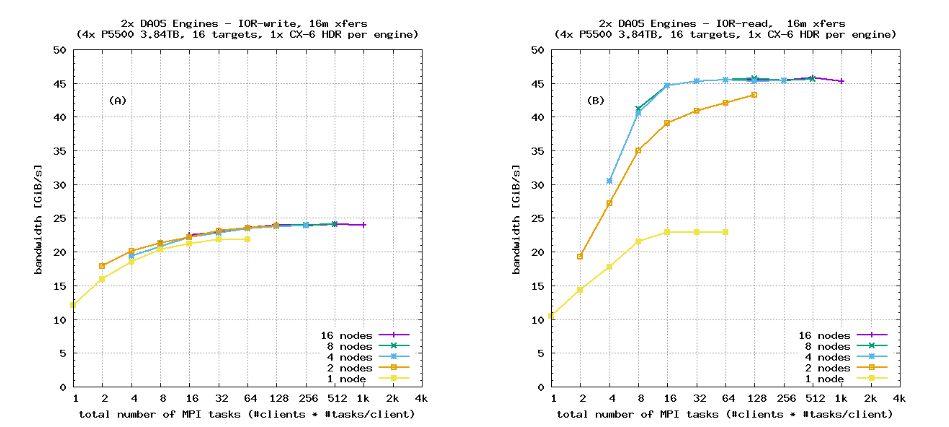
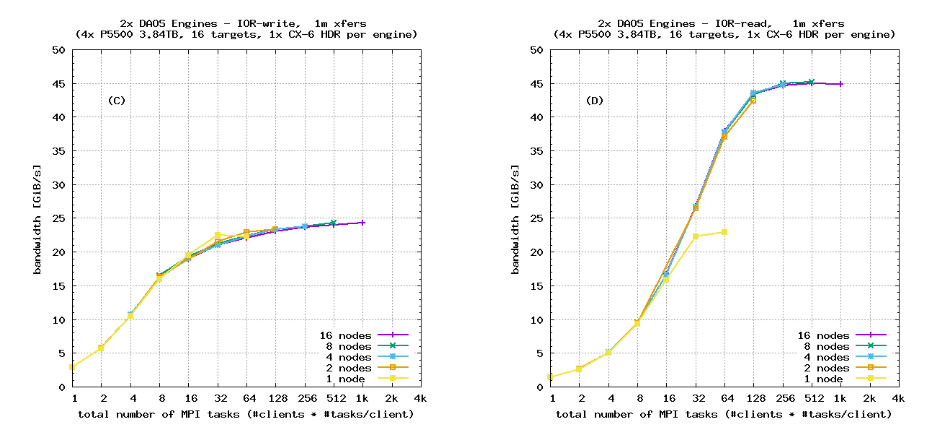
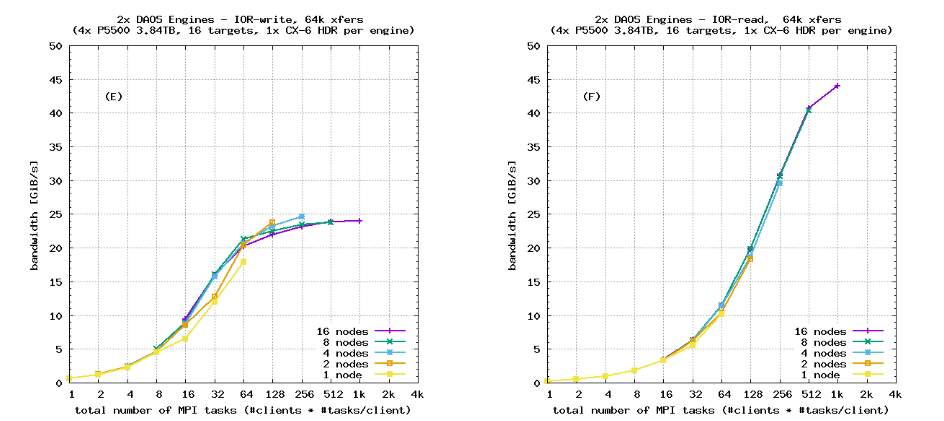
请注意,IOR的DFS后端的可选参数–dfs.chunk_size可以用于调整从单个IOR任务发送的最大I/O请求大小。在本研究中,所有运行都使用了默认的块大小1 MiB。当IOR transferSize大于DFS块大小时,来自IOR任务的单个I/O传输将被分解成多个块。这与增加每个客户端节点上的MPI任务数具有类似的效果。图6和图7证实了这种行为:与使用IOR transferSize为1 MiB(与DFS块大小匹配)的基准测试相比,使用transferSize为16 MiB的运行的扩展曲线向左移动。
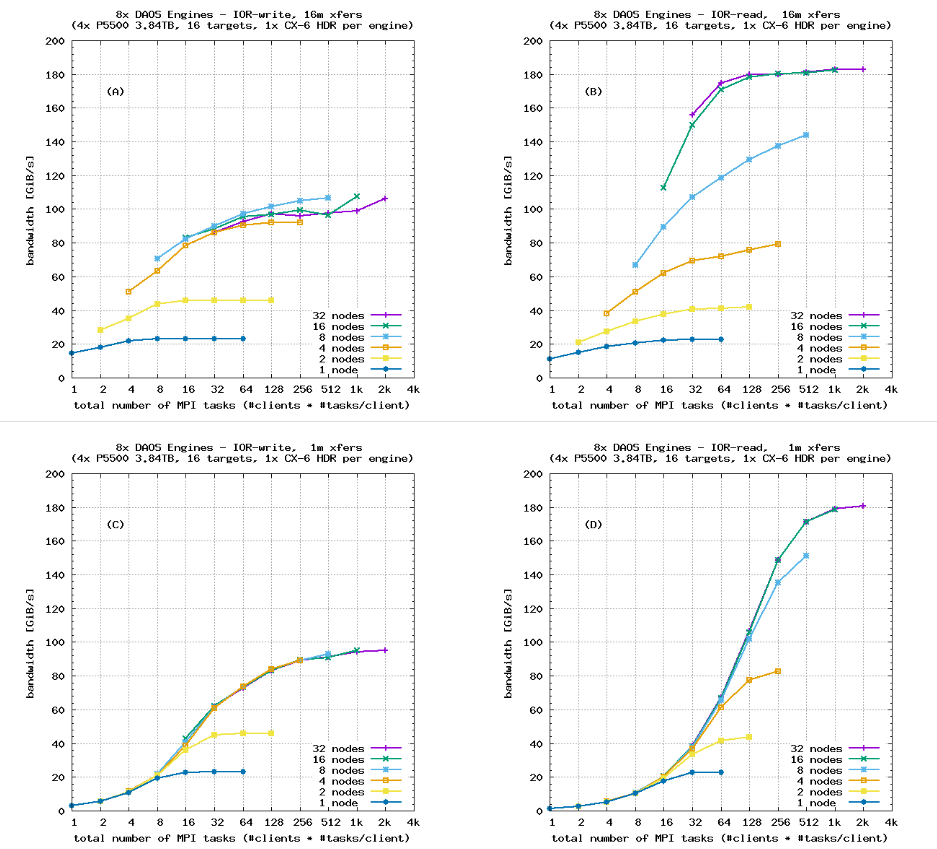
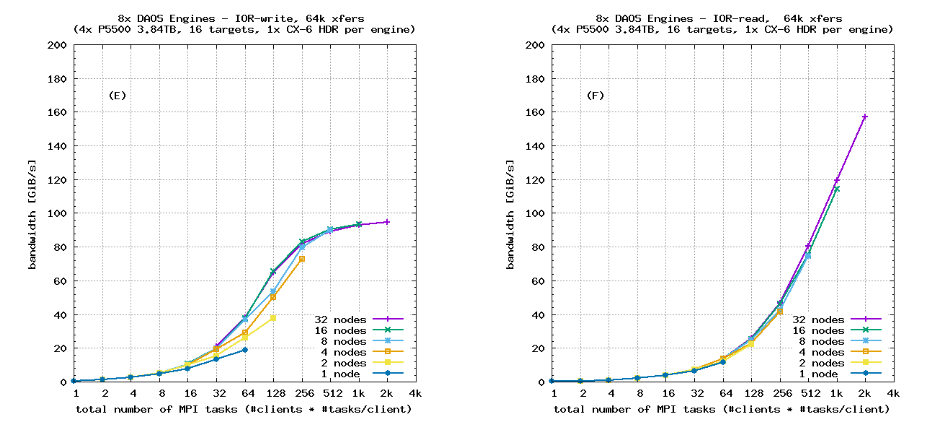
图6和图7中64 kiB传输的扩展曲线与1 MiB传输相比向右移动。但这并不反映每个客户端节点的有效MPI任务数的减少:DAOS DFS API不执行写回缓存,并且每个64 kiB I/O请求会立即发送到服务器。64 kiB传输的右移是由于NVMe SSD需要更高数量的在飞行操作(块存储术语中的较高队列深度)来用较小的I/O请求饱和其峰值带宽。
IOR-Hard的带宽与DAOS引擎数量的扩展
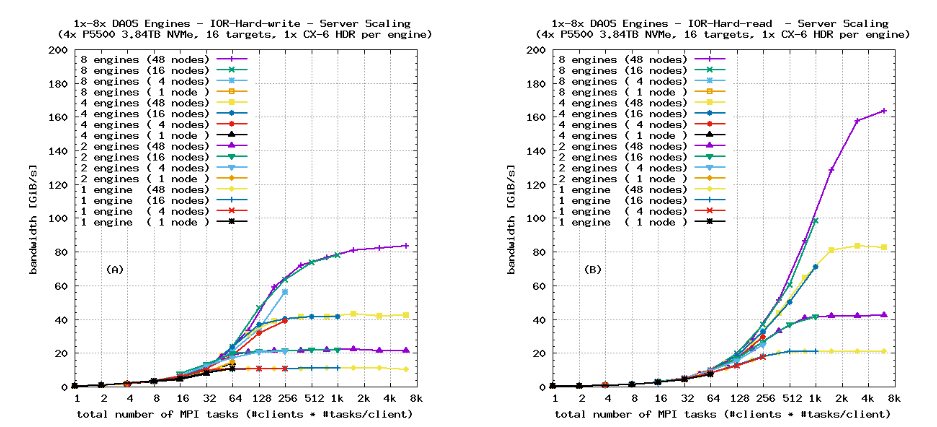
图8显示出“IOR-Hard”的性能随服务器数量的增加而扩展,与图7中图(E)和图(F)显示的64 kiB顺序传输类似。与第5.2节一样,这些测试使用了SX对象类别(条带,无数据保护)。结果验证了对于这种工作负载,DAOS确实基本消除了软件瓶颈,并且在可用的硬件资源下良好地扩展,即使在步进式访问模式中进行小而不对齐的写入。
数据保护(DAOS对象类别)对带宽的影响
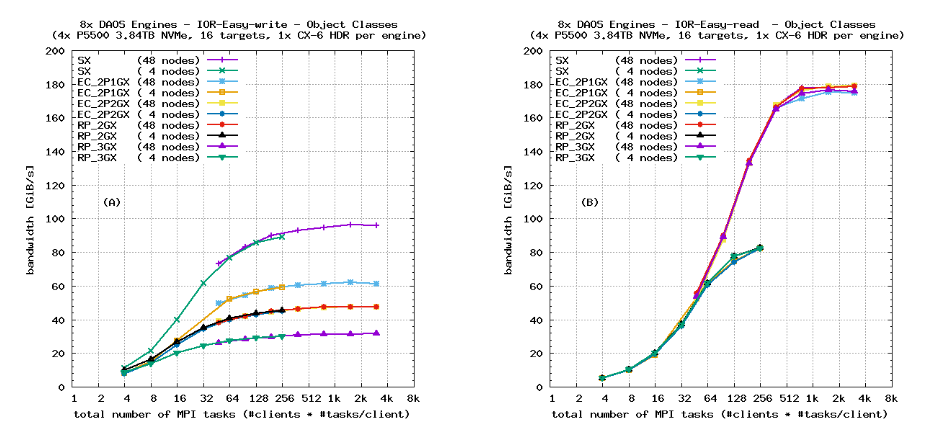
图9显示了在四个DAOS服务器上运行的“IOR-Easy”带宽测试的DAOS性能,作为用户选择的数据保护方案的函数,这些方案已在表1中总结。在较少的服务器上运行这些基准测试是不可能的,因为数据保护方案需要足够多的存储引擎,这些存储引擎不共享共同的故障点,以便能够广泛分布数据副本或EC奇偶校验信息。结果与预期一致:
- 读取带宽不受数据保护方案的影响。在图9(B)中饱和于∼80 GiB/s的曲线显示了在四个客户端节点上的测试,带宽受限于4个HDR客户端网络端口而不是服务器端带宽。在48个客户端节点上的测试会使服务器上的8个HDR链接饱和。
- SX测试的写入带宽接近于四个DAOS服务器的NVMe写入带宽(每个硬盘3.26 GiB/s * 8个硬盘/服务器 * 4个服务器 = 104 GiB/s)。这对应于图7中的图(C)和(D)。
- EC_2P1GX基准测试的写入带宽降低到SX带宽的∼66%,因为每两个数据条带中有一个附加的奇偶校验条带。EC_2P2GX的带宽降低到SX带宽的50%。对于更大的集群,EC_8P2GX或EC_16P2GX之类的更宽的EC编码提供更好的可用容量和更高的写入带宽,但对于本研究中使用的4个服务器来说,没有足够的DAOS引擎可用于这些EC编码。对于非常大的存储环境,还可以使用具有超过两个奇偶校验条带的对象类别来防止更高概率的相关故障。
- 对于复制,RP_2GX基准测试显示了与EC_2P2GX测试相同的性能概况:这两种保护方案都会产生50%的开销。在数据保护方面,EC_2P2GX对象类别优越,因为它可以防止两个故障,而RP_2GX只能容忍单个故障。复制在小型I/O请求方面具有卓越性能(这通常在EC中更昂贵),但缺点是更高的容量开销:如上所述,更大的集群允许更宽的EC编码(提高可用容量和写入带宽),而2路复制的开销将保持恒定。
- 如预期,3路复制对象类别RP_3GX的写入带宽仅达到SX写入带宽的∼33%,因为每个数据块的两个附加副本。
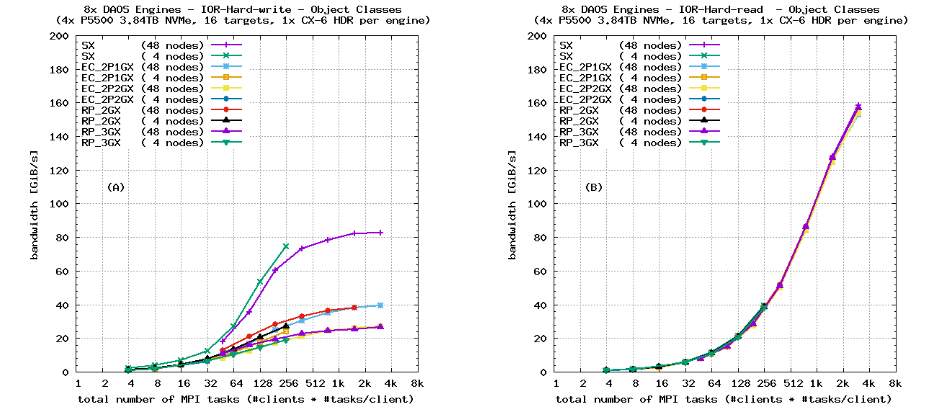
图10显示了在四个DAOS服务器上运行的相应的“IORHard”性能扩展,对应于图9中的相同一组DAOS对象类别。与图9不同,这些基准测试现在仅使用了47008字节的更小I/O传输大小,以及图3所示的IOR“周期性”I/O模式。
- 读取性能不受复制或EC的影响:虽然图10(B)只能达到∼160 GiB/s,但将客户端基准测试的大小从48*64=3072个MPI任务逐渐增加到这里应最终达到与图9(B)相同的服务器端网络带宽,即8个HDR端口。
- 图10(A)中的SX写入带宽对应于图8(A)中的8个引擎结果。两者都没有达到∼104 GiB/s的理论最大值,因此与“IOR-Easy”测试用例相比存在一些效率问题,但带宽仍非常接近顺序“IOR-Easy”基准测试。
- 复制和EC对象类别的写入带宽反映了与SX测试相对应的数据保护开销。唯一的异常情况是EC_2P1GX情况,其性能下降显著高于预期。这需要通过更多基准测试来验证根本原因-可能是基准集群中的操作问题或DAOS代码中的问题。
元数据速率
IO500基准套件规定了七个代表性的mdtest基准测试,以及一个“find”命名空间遍历。虽然mdtest基准测试的设置是固定的,但IO500规则允许优化“find”基准测试(但不指定需要报告什么)。这意味着比较不同IO500列表条目的“find”结果是困难的。DAOS也有一个优化的“find”实现,但本研究仅研究了七个明确定义的mdtest基准测试,并且不考虑“find”测试。所有元数据基准测试都使用SX目录对象类别和S1文件对象类别进行了测试。
IO500的七个元数据基准测试在元数据速率的绝对值以及其扩展行为方面表现出不同的行为。在观察到扩展限制时,分析单个元数据操作是有益的。但为了简化整体扩展行为的呈现,本文遵循IO500的惯例,并呈现了一个“mdtest分数”,这是七个mdtest基准测试几何平均值。这与IO500的“元数据分数”接近,但不包括其几何平均值中的“find”结果。在参考文献[20]中可以找到七个元数据操作的个别扩展图表示例,该文献报告了一个类似的在ARM64上的性能研究(规模要小得多)。
元数据随每个引擎的CPU核心数量的扩展
在DAOS中,存储目标是DAOS存储引擎内的服务线程,用于管理NVMe和SCM容量的一部分。每个目标都需要一个物理CPU核心来运行,因此引擎的每个目标的最大数量受限于CPU的物理CPU核心数量。DAOS还可以利用一些额外的辅助线程,例如用于处理后台聚合的线程-这些线程在这里不予考虑。需要注意的是,每个DAOS存储引擎的目标数必须是每个引擎的NVMe SSD数的倍数,以确保平衡的存储布局。本研究中使用的服务器每个引擎有四个NVMe SSD,因此在图11中,所有测试都已使用每个引擎4、8、16和32个目标(标记为“tpe”)进行了重复测试。
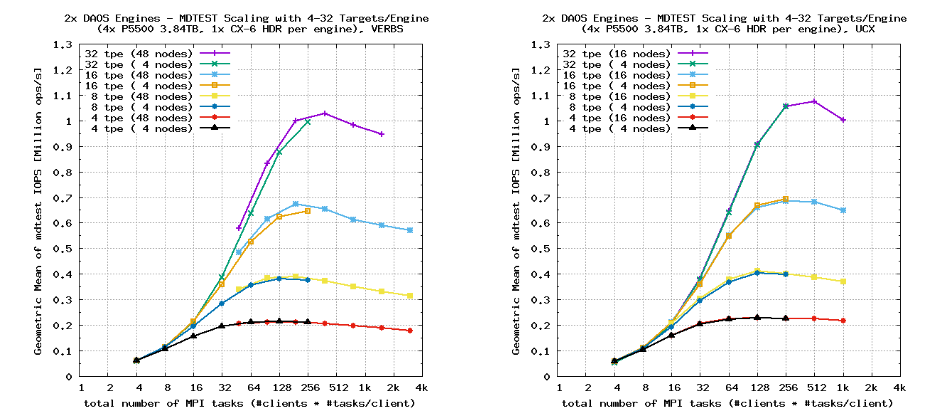
从扩展图表中可以清楚地看出,对于两种网络提供者,元数据速率随目标数量的增加而增加。虽然扩展并不完美,但对于具有大量元数据流量的工作负载,将DAOS服务器配置为具有高核心数量的CPU可能是有益的。DAOS解决方案的整体价格/性能还将取决于NVMe SSD和网络端口的相对成本,因此最佳配置需要根据具体情况确定。
元数据随DAOS引擎数量的扩展
DAOS具有完全分布式的元数据,这使其与许多其它使用专用元数据服务器的并行文件系统不同。因此,验证随着更多的DAOS服务器添加到存储解决方案中,元数据速率是否会扩展是很重要的。
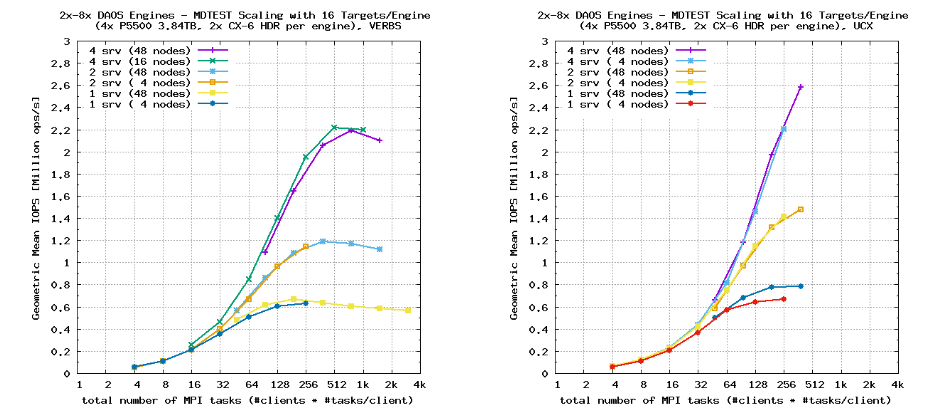
图12显示了将DAOS服务器的数量从一个增加到四个时的扩展行为。与图11一样,在左侧显示了libfabric/verbs提供者的结果,右侧显示了UCX提供者的结果。元数据性能随服务器数量的增加而扩展。这证明了完全分布式元数据的优势,以及DAOS数据模型在POSIX容器中的有效性。
对于libfabric/verbs提供者,扩展曲线在某些MPI任务数量处显示出最大的元数据速率,并且对于更高数量的MPI任务,会发生轻微的退化。分析单个mdtest操作显示,这种效果主要是由stat()和delete()操作引起的。需要对这种效果进行更详细的研究,以确定退化的根本原因。
本研究中使用的DAOS 2.3.101代码级别中,UCX提供者支持仅为技术预览版本,并且我们观察到在高数量的MPI任务下存在一些不稳定性,从而阻止了使用1024个或更多个MPI任务运行mdtest。这些问题将在DAOS 2.4版本中得到解决,该版本中UCX提供者将得到全面支持。但即使在较小的规模下,UCX提供者的元数据速率也比libfabric/verbs提供者高10%至20%。这是令人鼓舞的,预计UCX提供者相对于libfabric/verbs提供者的优势应该会随着系统规模的增加而增加。验证这一假设是未来扩展研究的课题。
总结和结论
本研究验证了DAOS数据和元数据操作在广泛的配置集中的性能。特别是,我们已经证明了DAOS可以实现与理想的“IOR-Easy”硬件带宽相媲美的“IOR-Hard”性能,对于这种测试情况,传统的并行文件系统[9–11]很难实现良好的性能。
我们已经展示了用户可选择的数据保护和数据分布方案如何用于适应已知的工作负载模式。DAOS复制和纠删码对象类别(与无数据保护相比)的观察带宽与预期行为一致:读取没有性能影响,写入性能开销与预期的副本或奇偶数据的额外写入操作相符。未来的工作应该将这些测试扩展到更大的存储集群,采用更宽的EC码,以从更好的可用容量和更高的写入带宽中受益。
在元数据方面,已经显示出DAOS随服务器端资源(存储设备和CPU核心数量)的增加以及客户任务数量的增加而扩展。某些元数据测试在高MPI任务计数下显示出扩展的限制(主要是stat()和delete()操作)。未来的工作应该更详细地分析这些限制。特别是即将到来的ANL Aurora [21]和LRZ [22] DAOS安装将允许超越目前研究可以涵盖的范围进行扩展研究。