社交媒体和物联网服务通常都有很大的工作集,由数十亿个小对象组成。为了提升数据库系统的性能,降低成本,基于闪存的缓存系统显得非常重要。相比于DRAM与NVM,闪存缓存系统价格低廉。但是用闪存作为小对象缓存盘面临着严重的写放大现象与寿命问题。Kangaroo利用分层设计的思想,结合log-structured cache与set-associative cache的优点,以最小的内存开销、成本开销,实现了高命中率的闪存缓存系统。
背景
许多web服务需要对数十亿个小对象实现快速访问,而每个小对象只有几百个字节。为了实现这一点同时考虑实际生产效益,缓存系统必须做到同时低成本,大容量与高性能。DRAM与NVM虽然性能好,但容量小,价格过于高昂。而闪存技术的发展使得闪存兼具性能与成本的优势。然而,闪存作为小对象缓存也面临着严重的寿命问题,这与闪存的特性有关。闪存读写的最小单位是页面(KB级粒度),而小对象通常不到一百个字节。因此,闪存缓存系统的简单部署势必会导致严重的写放大现象,加剧磨损问题,降低固态硬盘的使用寿命。
问题
传统的缓存策略
- Log-structure cache: 该策略将数据顺序批量写到闪存上,可以有效减小写放大现象。为了记录对象在闪存中的位置,每个对象需要在内存中保留一个索引。对于一个比较大的工作集,数十亿个对象索引的内存开销巨大。
- Set-associative cache: 该策略根据对象的键值将对象存放到不同的set中,就像CPU的cache,利用对象的键值来确定对象的实际存放位置,消除了内存索引的开销。但是该策略会将多余的字节写入闪存,每个对象的修改都需要重写整个闪存页面,严重增加了闪存的写入量。
闪存缓存的写放大
- Device-level write amplification: 设备级写放大发生在闪存转换层(FTL),即闪存内部的写入量超过主机端的写入量。当闪存内部空闲空间不足时,FTL除了应对主机端的写入,还需要执行垃圾回收来把部分有效页面迁移到新的块内。
- Application-level write amplification: 应用级写放大是指应用程序需要重写一些已经存在的数据。当一个页面中的部分对象需要更新时,闪存需要读出整个页面,修改后再进行重新写操作。
小对象使得闪存缓存系统极具挑战性,在存储设备中需要单独记录数十亿个小对象,可能需要巨大的元数据索引结构,消耗大量的内存资源;如果索引位于闪存上,又会引入额外的写放大现象。先前的工作没有解决如何以低成本在闪存中缓存小对象的问题,log-structured cache需要过多的DRAM,而set-associative cache 会带来严重写放大问题。
设计
Kangaroo是一种闪存缓存设计,其针对数十亿个小对象的场景进行了优化。它的设计目的是最大限度地提高命中率,同时最大限度地减DRAM 的使用和闪存写入。Kangaroo 采用分层设计,跨内存和闪存,将log-structured cache与set-associative cache结合。为了减少闪存的写放大,Kangaroo利用Klog组件去缓存最近写入的对象;为了减少DRAM的索引开销,Kangaroo 利用Kset组件来缓存绝大多数对象。同时再Klog向Kset的转化过程中,kangaroo利用了哈希冲突的特点,当大量的对象被映射到同一个Kset时,这些对象会批量写入Kset,既提升了性能又减小了闪存的写放大现象。
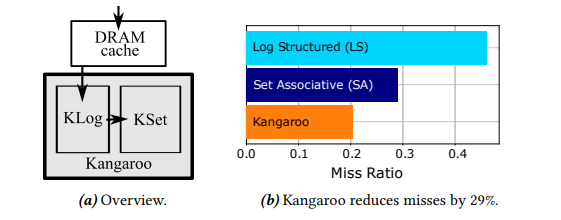
Kangaroo主要通过以下三个策略来减少闪存写入,减小内存开销,提高缓存命中率。
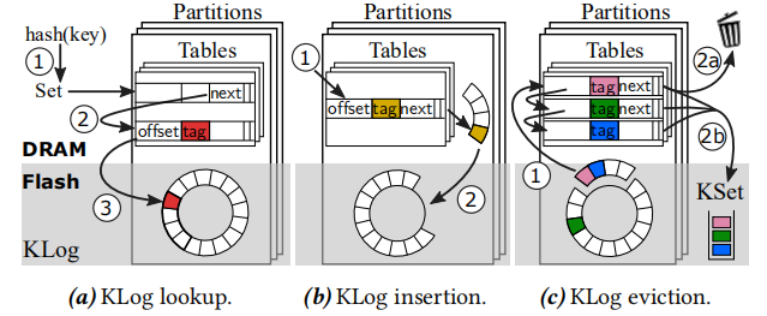
1. Partitioned Klog:Klog内部结构为多个分区,每个分区有自己独立的日志结构和DRAM索引结构。同一个Set的所有对象都会位于同一个分区表。利用hash冲突的特点,每个对象索引的next指针指向同一个set的下一个对象索引。采用拉链法解决哈希冲突使得Kangaroo可以高效的遍历位于同一个set的对象,从而实现批量的写入,减小写放大。
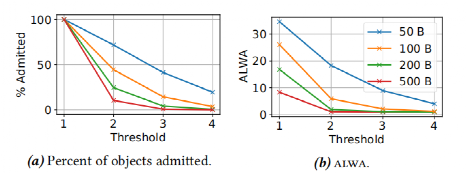
2. KlogàKset:当数据从Klog向Kset迁移时,Kangaroo利用准入策略对对象进行筛选。当每次待写入的对象数量少于阈值时,Kangaroo会丢弃该数据,多于阈值时才允许对象从Klog迁移到 Kset中。采用一个合适的准入阈值可以使得该策略有效减小应用级写放大现象。此外,热点数据如果没有发生哈希冲突,可能会被剔除。Kangaroo为了解决这一问题,会使得热点数据重新进入DRAM buffer,等待哈希冲突,提高缓存的命中率。
3. RRIParoo:Kangaroo会对Kset中的对象进行管理,决定需要剔除的数据。传统的驱逐策略通常有较多的DRAM开销,而RRIParoo给每个对象分配1bit,当对象最近被访问过,该位置为0;同时结合经典的RRIP缓存替换策略来智能选择需要驱逐的数据。
最后,简单介绍下Kangaroo的基本操作流程,如图四。
1. 查找
首先在DRAMcache中查找对象,若命中则返回,若缺失则进入Klog中查找;若命中则返回,若缺失则查找Kset的布隆过滤器;若存在则查找Kset,若找到则返回,若缺失或假阳性则从底层数据库中获取数据。
2. 插入
首先数据写入到DRAMcache中,其有一定的概率会直接丢弃,或进入Klog;若进入Klog,则可能发生Klog到Kset的迁移。若未达到准入的阈值,则数据被丢弃,若达到准入阈值,则修改布隆过滤器标志位,并把数据写入到Kset中。

实验效果
论文作者团队中将 Kangaroo 实现为CacheLib 中的一个模块,并用真实的设备,Facebook和Twitter的真实负载进行了性能测试。实验中Kangaroo的基本配置参数如下表。

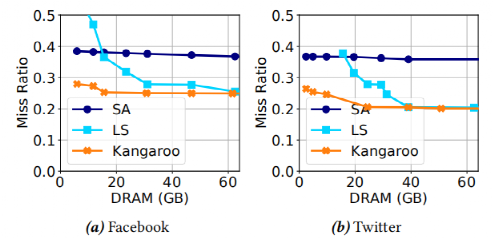
实验人员首先限制了DRAM的使用,从图五中我们可以发现,LS策略由于需要大内存来存放索引,因而随着内存的增加,缓存缺失率下降;而SA策略基本不需要DRAM资源,性能随着内存容量的影响不大;而Kangaroo能以以极小的内存开销实现了较低的缓存缺失率。
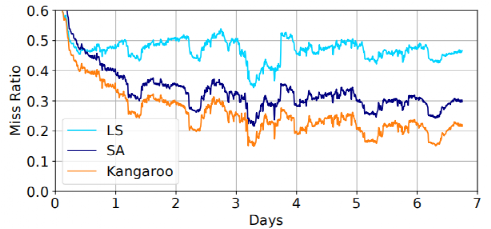
下图显示了三种策略在Facebook连续7天的负载下的表现,实验人员在这组实验中限制了闪存的最大写入速度。Kangaroo的缓存缺失率与 SA 相比减少了 29%,与 LS相比减少了 56%。这是因为 Kangaroo有效地利用了有限的DRAM ,减少了闪存写入。
总结
Kangaroo结合了Log-structured cache与Set-associative cache的优点,减少了小对象闪存缓存系统的DRAM开销与闪存写入量,降低了缓存系统的成本,提升了生产系统的性能。
