摘要
在生成式AI(GenAI)领域存在一个鲜为人知的问题,它可能会阻碍许多用户实现其目标:其IO模式可能会对传统存储系统造成巨大压力。解锁GenAI的全部潜力的关键在于高效利用拥有数十亿参数的高质量多样化训练数据。有效训练模型所需的大量数据,以及获取、存储和处理这些数据都可能带来挑战。
在GenAI操作管道中,包括数据摄取、预处理、嵌入、微调,以及广泛的验证/回测等操作,IO模式变化多样,可能导致IO混合问题,即不同工作负载,包括事务性和流式IO,竞争导致性能不佳的情况。IO混合会降低生成式AI中的结果产出时间,降低计算GPU和CPU的利用率。我们已经分析了许多客户环境,以确定IO模式及其对GenAI数据管道的影响。
数据挑战
在生成式AI管道中,无论是在本地还是在云端,存在两个显著的挑战。首先是所谓的“数据停滞”现象。如果我们回顾10年前,当许多现代存储和文件系统解决方案尚未普及时,用户会根据不同IO的性能需求将数据分隔存储在不同的存储空间中,以优化各个步骤的性能。
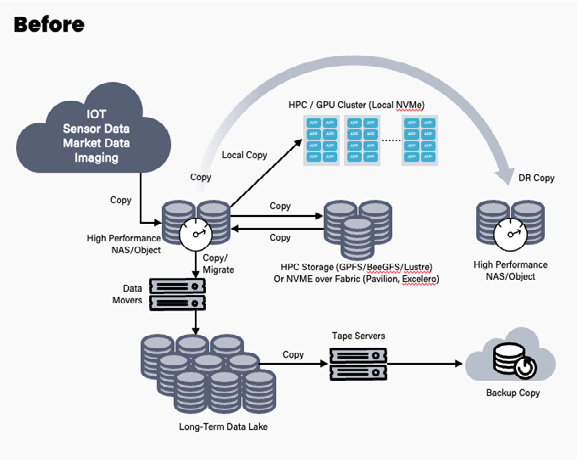
然而,如今,由于资源的可用性压力,用户倾向于合并工作流程,使用单一的存储平台来处理整个数据管道,以便更容易管理,避免“存储空间扩展”,并提高总体成本效益。我们通过高性能的数据平台实现了这种合并。
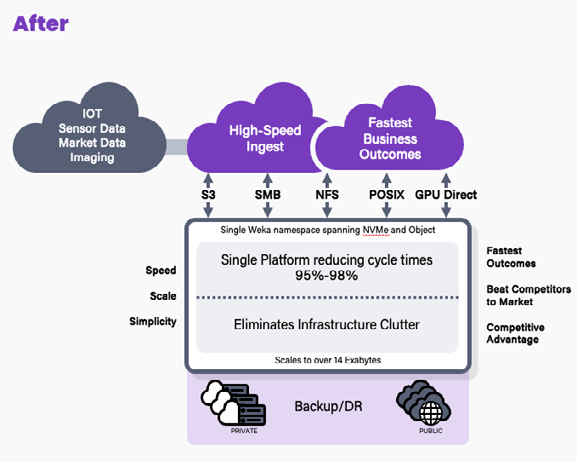
在大多数GenAI管道中,涉及到在CPU和GPU上进行处理的多个步骤。即使某些部分可能更适合在CPU上执行,用户也不希望不断在不同的存储空间之间复制数据,因为这会导致数据停滞问题,降低GPU的利用率。因此,他们更倾向于将数据合并到单一的数据平台上。然而,这也带来了另一个挑战:所谓的“IO混合”问题。
尽管上文提到了虚拟机合并方面的IO混合问题,但此概念同样适用于生成式AI数据管道。
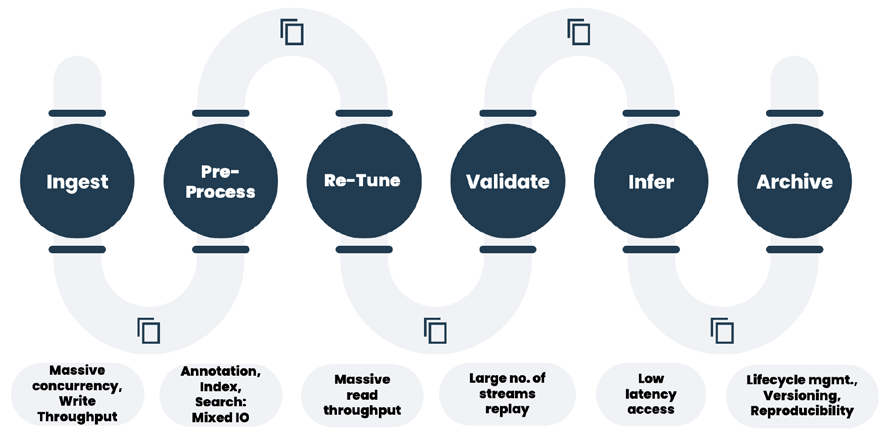
在GenAI数据管道中,包括数据摄取、预处理、嵌入、微调以及广泛的验证/回测等操作,IO模式各异,可能导致IO混合问题,即不同工作负载之间的事务性和流式IO争用,从而导致性能不佳。这种IO混合会影响生成式人工智能中的结果产出时间,并减少计算GPU和CPU的利用率。我们已经分析了许多客户的环境,以确定IO模式及其对GenAI数据管道的影响。
自然语言处理(NLP)
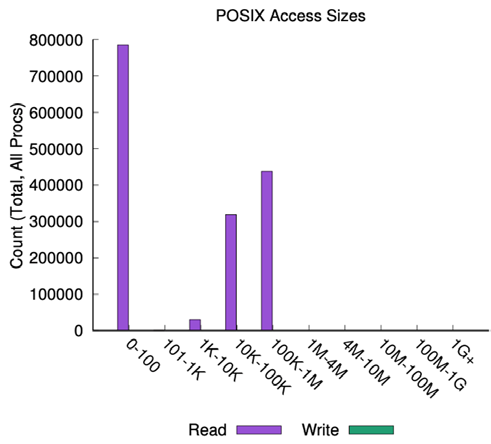
本客户案例涉及构建用于处理音频文本和音频操作的NLP模型。在此IO模式中,他们进行了大量的自然语言解析。
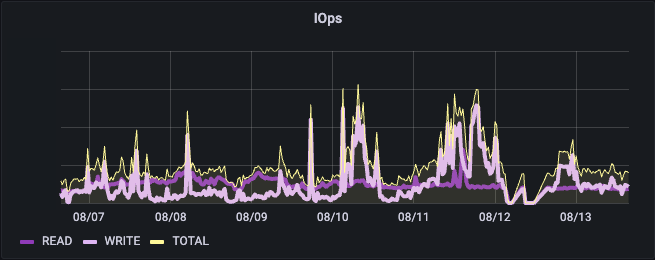
在该环境中,我们看到这是一个完全混合的IO管道,其中包含相对一致数量的读取操作,以及写入操作的IO峰值。这些信息可以映射到后端服务器的负载情况。
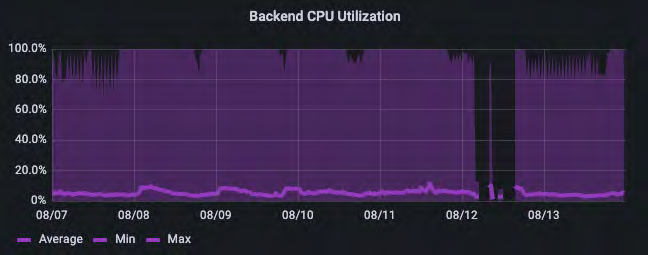
深紫色和浅紫色分别表示最大利用率和平均利用率,显示了AI管道中IO的极其突发性质。了解这种模式的细节至关重要。如果我们只看平均值,可能会认为系统的利用率只有5%。但实际情况是,它每隔几分钟就会剧烈地上下波动,经常会达到80-100%的峰值。
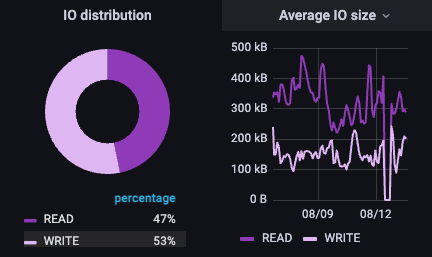
对于该NLP管道,读/写比例为47/53,但值得注意的是IO的大小:大IO是读取进来的,而较小的IO是写出的。在这种情况下,客户已经将一些通常不到100k大小的小样本拼接在一起,形成了一个更大的文件,并且正在对该文件进行读取,就好像它是一个数据流。较小的写入IO很可能是在NLP工作流中进行的检查点操作。这种数据的广泛差异再次挑战了数据平台,需要在这种工作流中容忍多维度的性能。
AI/ML模型开发
此客户案例涉及在业务应用中构建文本-文本和文本-操作的NLP和ML功能的组合。与NLP用例相比,他们的数据管道更为分隔,重叠较少。在开发过程的生命周期中,他们的IO发生了显著变化。尽管仍然处于生产工作负载阶段,但他们计划在不久的将来进行全面扩展,这将增加数据管道各部分的重叠。
正如我们在这里所看到的,在摄取和预处理阶段,他们具有混合的IO模式。IOPs和吞吐量都与读占48%、写占52%的比例相匹配。IO大小再次倾向于大量读取和较小的写入。
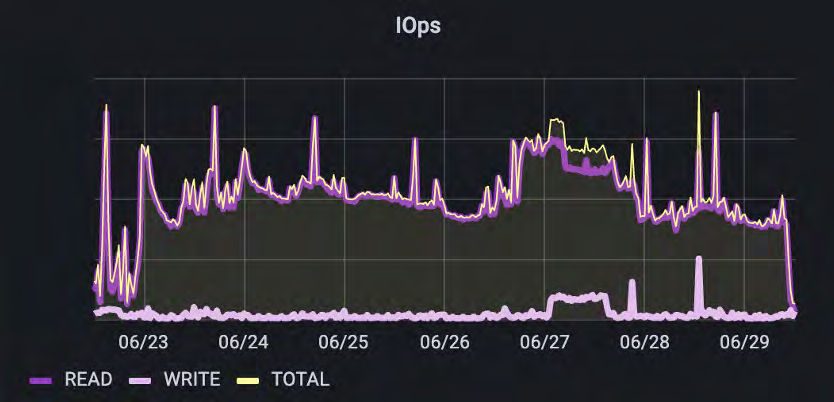
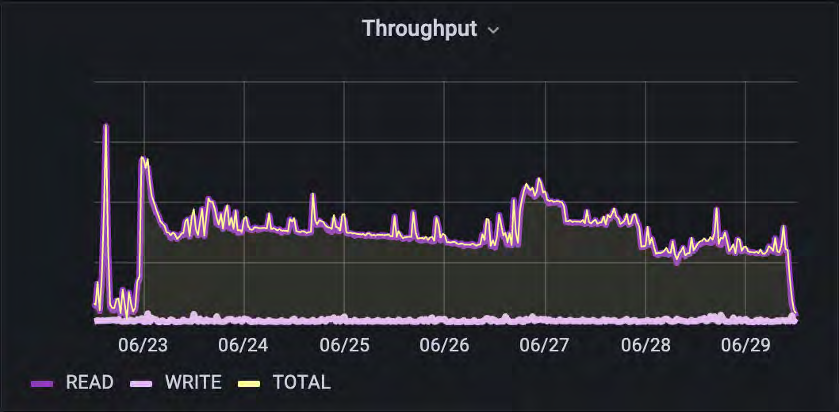
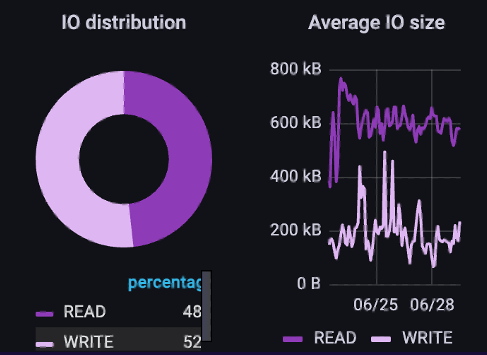
请注意,读取IO大小的变化较小。客户正在使用经过预处理和标准化的数据来构建他们的H5文件,并且倾向于具有更一致大小的数据,因此反映了读取IO大小范围较窄的情况。
图像识别/计算机视觉训练
此客户案例涉及数据管道的一个子集。在这种情况下,他们几乎完全依靠自动化训练循环对摄取的图像进行训练,其中大部分预处理已经完成。与之前展示的元数据示例不同,因为该客户没有告诉我们他们使用了哪些工具(如Tensorflow、Pytorch等)。
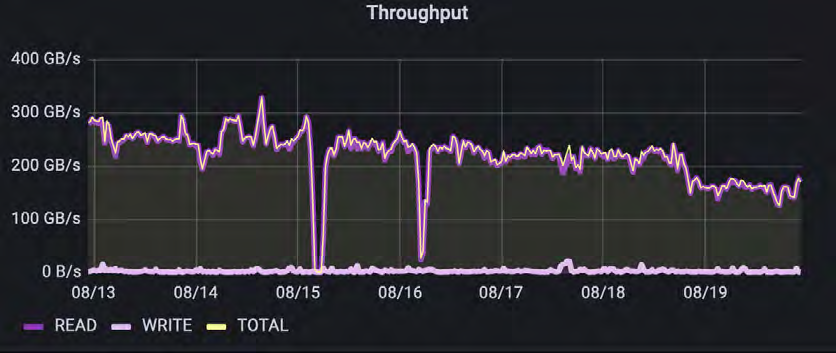
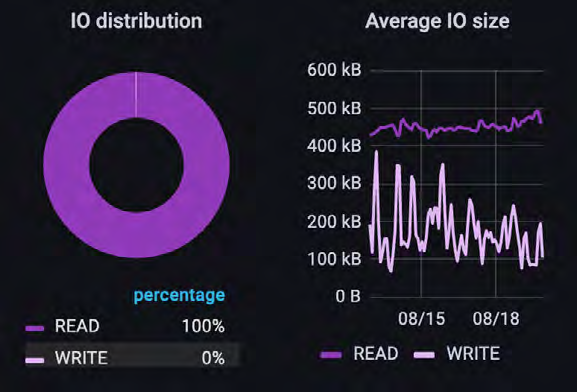
正如预期的那样,总体吞吐量由读取操作主导。虽然读取的IO大小在400k-500k范围内非常一致,但写入的差异很大。大多数写入操作要么是对文件的元数据更新,要么是小型进程数据的回写,还包括检查点操作。虽然测量的IO是实际数据传输的IO,但还可能存在不会显示为IO的重要元数据操作。这些元数据操作可以显著影响训练模型的性能。
元数据处理
在处理大量小文件时,通常被低估的一个领域是元数据的总体负荷,这是许多AI工作负载的主要数据样式。举个例子来说明这种元数据开销,我们研究了一个使用TensorFlow在Imagenet上进行深度学习管道的客户,训练数据库包含1400万张图像。
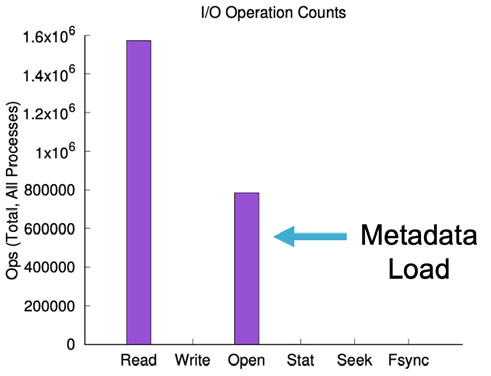
在几乎全是读取操作的训练过程中,超过30%的操作是打开文件操作。这是一个对数据平台扩展能力进行测试的重要负荷。我们发现,这种开销可以根据使用的训练数据和训练文件的大小而变化,范围从25%到75%不等。这种类型的元数据开销是深度学习训练和转移学习中的特征。然而,这不仅仅适用于训练过程。例如,我们曾看到在查看摄取的所有非结构化源数据时,大部分IO都来自于查找需要拉入预处理的文件的Stat和Seeks操作。这种“隐藏的IO”可以在工作负载扩展时对数据平台产生负担。想象一下,一个需要进行1000万次读取IOP操作的环境,还需要额外处理500万个元数据IOP操作。
文件的大小也很重要。在同一TensorFlow管道中,我们看到数据的大小要么非常小(不到100字节),要么在10KB到1MB的大小范围内。由于文件大小的差异,数据平台需要能够同时处理非常小的随机IO和相对更为顺序的IO。
结论
生成式AI和AI数据管道面临着多重挑战,以充分利用最新一代GPU和CPU的高性能。这些挑战包括两个主要方面:数据流动问题和IO混合问题。在数据流动问题中,不同部分的AI数据管道需要在不同的存储平台之间传输数据,这可能导致数据复制和停滞。而IO混合问题是指在同一数据平台上同时运行多种不同的IO操作,其中包括读取和写入,导致IO的比例和大小不断变化。这些问题在各种AI用例中都普遍存在,表现出以下持续趋势:
- IO操作在短时间内会突然增加,尤其是当多个数据管道部分同时运行时,这种情况更加明显,导致IO比例和大小的多样性。
- IO读写比例以及IO操作的大小变化很大,这可能在数据管道的不同阶段表现出相对一致,但在其他阶段可能有显著差异,包括读取和写入之间的差异。
- 延迟是GenAI环境中整体性能的主要衡量指标。因为AI操作通常需要保持一致性(例如微调基础模型或创建和嵌入特征),所以低延迟对于实现一致性的所有操作都至关重要,使AI流程可以更快地迭代到下一步。
- 元数据开销是一个重要问题,不论IO配置或用例如何,元数据查找和操作的开销都可能占据系统操作的25-75%。这包括文件打开、统计和查找等操作。
所有这些趋势都强调了需要一个能够满足各种生成式AI和AI环境性能需求的数据平台的必要性。许多数据平台之所以难以实现这种性能,是因为它们面临以下几个问题:
- 尝试通过将高速网络技术如RDMA与旧的文件协议(如NFS)堆叠以实现低延迟传输。尽管这种方法在某种程度上有效,但仍无法达到类似DPDK与NVMeoF等新技术提供的超低延迟水平。
- 文件系统延迟问题。如果文件系统本身没有设计用于有效处理大规模并行元数据和数据操作,那么最终会导致访问串行化,从而降低响应客户端IO请求的速度。
- 针对单一工作负载进行优化配置。许多平台已经选择优化特定性能配置,但这导致必须在平台内部复制数据以实现特定部分的优化,从而产生数据停滞问题。
- 无法处理大量小文件(LOSF)问题。由于基础模型和其他大型学习模型需要处理数百万甚至数十亿的训练数据文件,许多平台在处理这些非结构化数据时遇到问题。一种解决方法是将数据合并成较少数量的大文件,但这可能引发其他访问问题,并可能增加延迟。
我们的解决方案
我们的数据平台为生成式AI提供了最快、最可扩展的文件系统,无论是在本地还是在云端的模型开发的各个阶段,都能够满足开发人员对性能的高期望,同时也兼顾了云计算所承诺的可扩展性和便捷性。目前,已有超过200个领先的人工智能部署充分发挥了该平台的优势,以提高性能并实现成本效益,其中包括Stability AI、Midjourney和Adept.AI等。
我们的解决方案解决了在处理整合的GenAI工作流程时其他平台所面临的问题:
- 采用内核绕过技术,如DPDK和SPDK,结合高达400Gbit的高速网络速度,我们创建了一种类似于NVMeoF的数据和元数据的超低延迟传输层。
- 通过采用完全分布式和并行化的架构,我们致力于实现系统中任何操作的最低队列深度,能够同时处理各种类型的工作负载,同时保持一致的100-200微秒延迟。
- 我们的架构和低延迟关注使得它能够轻松处理高IOP、大规模流式传输或混合工作流程。这使得整合过程无需性能折衷,也无需不断调整系统的各个部分以优化工作流程的某一部分。
- 此外,我们的架构早期设计就充分考虑了EB级容量扩展挑战。这意味着您无需担心数据在平台中的位置。不论是在单个目录中有数十亿个文件,还是在单个命名空间中有数万亿个文件,我们的平台都能轻松应对。我们不需要强制拼接文件来弥补文件系统的限制,从而简化了您的工作流程和操作数量,以充分利用您的数据。我们能够轻松处理大量小文件(LOSF)问题。
Source: IO Profiles in Generative AI Pipelines


