
训练大型AI模型的世界不再是台式机或少数服务器的领域。大型AI研究组织正在使用很多加速器来训练大型模型。Google是AI训练的主要力量,设计了自己的加速芯片和系统,既可以用于内部目的,也可以通过Google Cloud平台租用给外部客户使用。在Hot Chips 32(2020)峰会上,我们有机会了解了更多有关Google TPU v3相比TPU v2 pod的改进的信息。
Hot Chips 32(2020)上的Google TPU V3
我们从基本的组成部分开始,就是上图的散热片下面的芯片,下图是TPU v3的基本框图。你可以看到两个核心,以及它们的向量,标量,矩阵乘法和转置/置换单元,也有HBM内存。你也可以看到与主机相连的PCIe接口以及两个核心之间的高速互连。
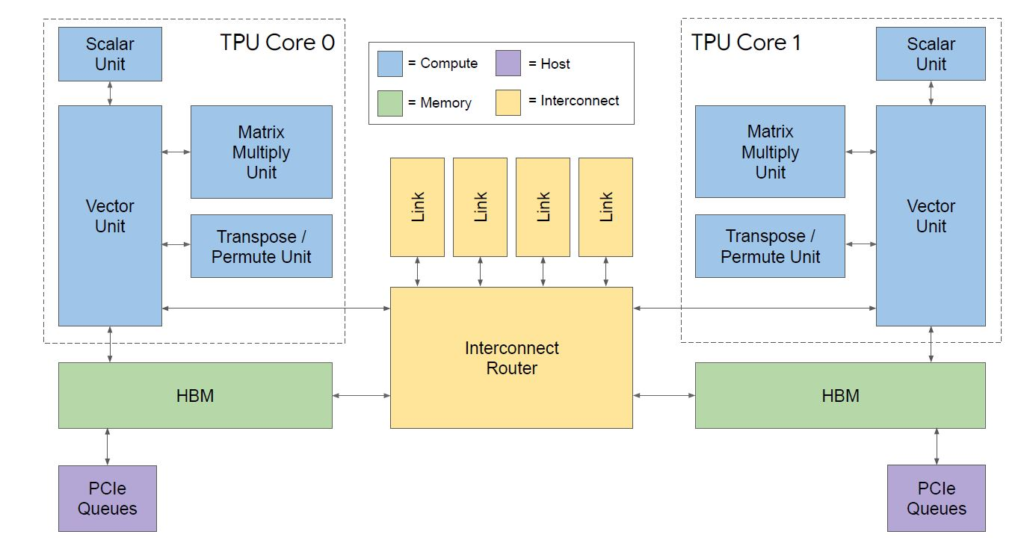
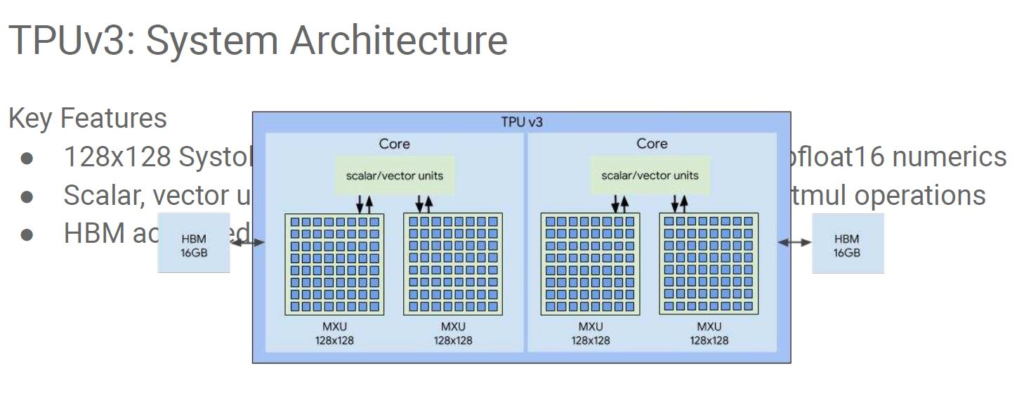
TPU v3的一大变化是矩阵乘法单元增加了一倍,就像HBM容量一样。下面是我们从Google演讲的PDF版本中获取的简陋的图片。演讲的材料没有显示在文本上的那个图表。Google可以建立大规模的AI训练系统并索引世界,这确实令人惊讶。
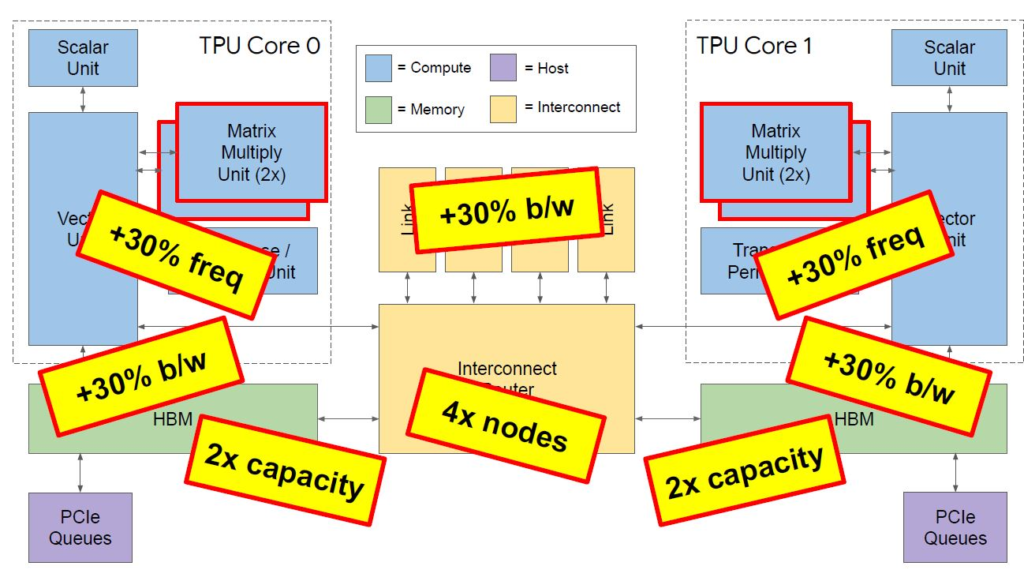
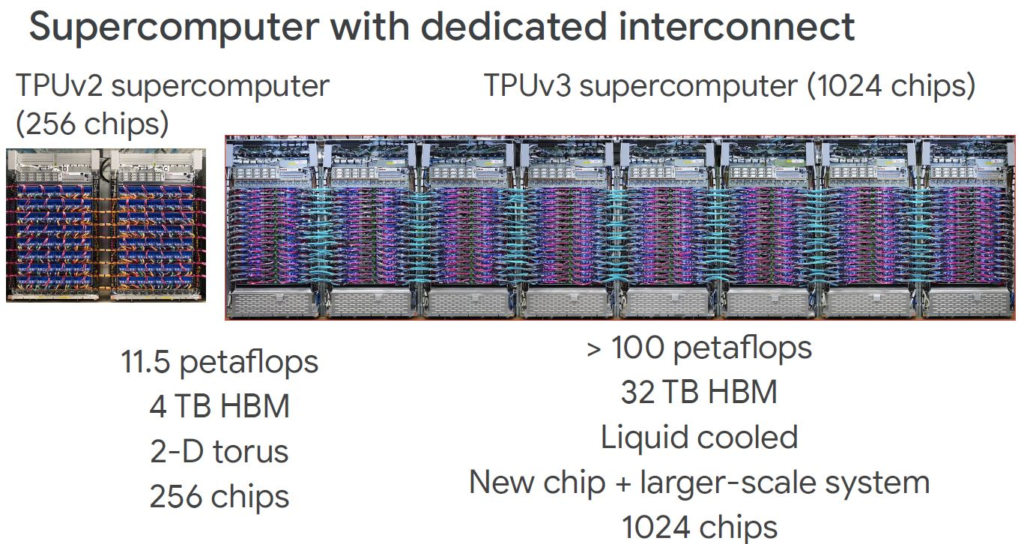
除了MMU和HBM容量增加一倍以外,还有许多其他的改进。核心频率,内存带宽和互连链路带宽也都增加了30%。当你在下面的图表中看到 “4x节点” 时,表示每个Pod的节点数正在扩展到上一代的4倍(从256个增加到1024个)。
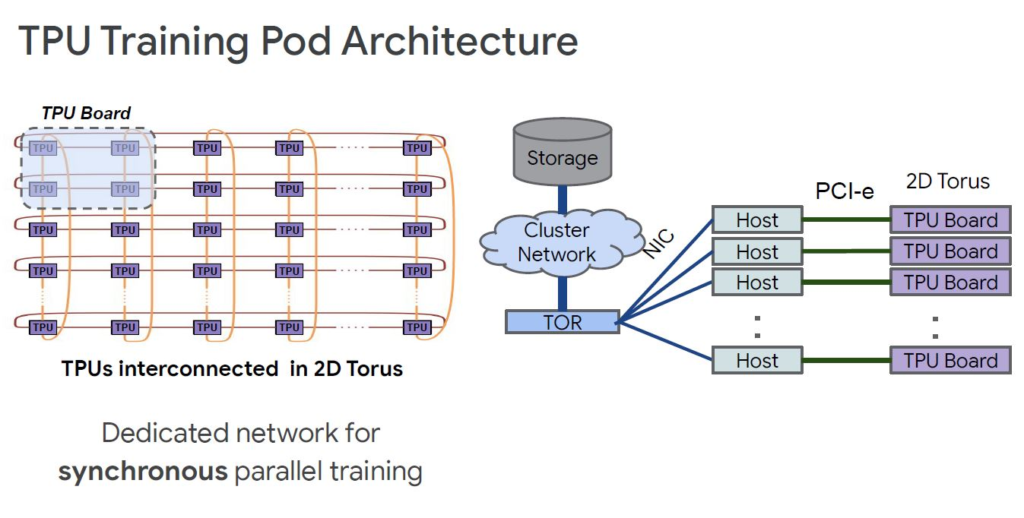
TPU通过2D Torus网络连接以进行高速加速器的通信。还有一个到主机的PCIe链接来提供到存储的链接。
退后一步,有很多人认为这与NVIDIA的做法完全不同。正如我们在”浪潮NF5488M5评测”以及”NVIDIA DGX A100和NVIDIA DGX A100 SuperPod外观”中所展示的那样,NVIDIA正在做类似的事情。NVIDIA A100(和V100)在HGX-2/HGX A100板上具有互连性。使用NVSwitch,可以从4x A100 GPU HGX Redstone Platform扩展到每个平台8或16个GPU。以NVIDIA-Mellanox的Infiniband通过GPU直接RDMA进行互联,并有效地绕开了通往主机的通道,以进入训练总线。对于存储,可以则通过另一个NIC返回到主机系统。
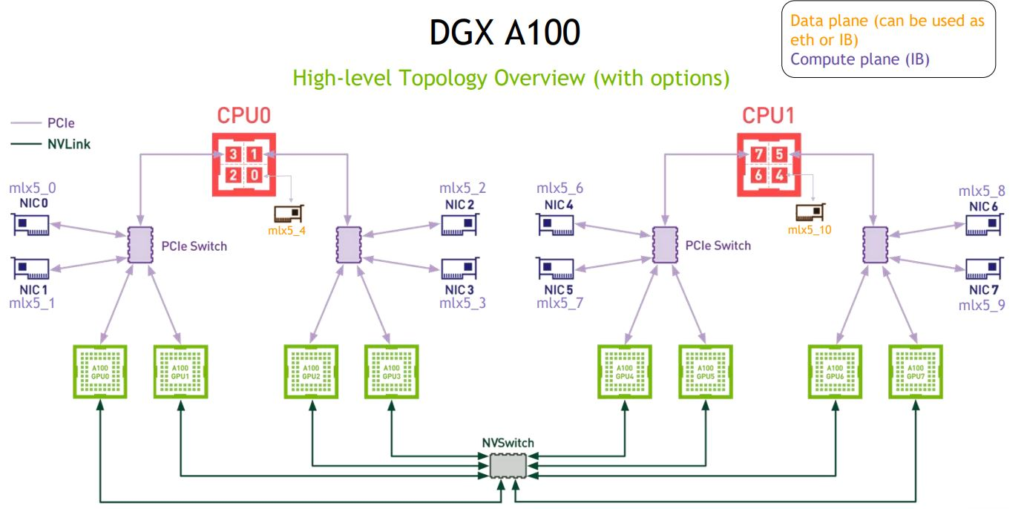
虽然存在一些差异并且有些差异还是非常大的,但我们只想指出,在上层解决方案的构建方式上确实存在很多相似之处。从这个上层层面上,我们正在将宝马与特斯拉(汽车)进行比较,而不是将宝马汽车与高速动车(子弹头火车)进行比较。
Google TPU v2是使用大型空气冷却的散热方案,而针对TPUv3,Google是使用的液体冷却方案,这样对服务器的高度的要求就降低了。
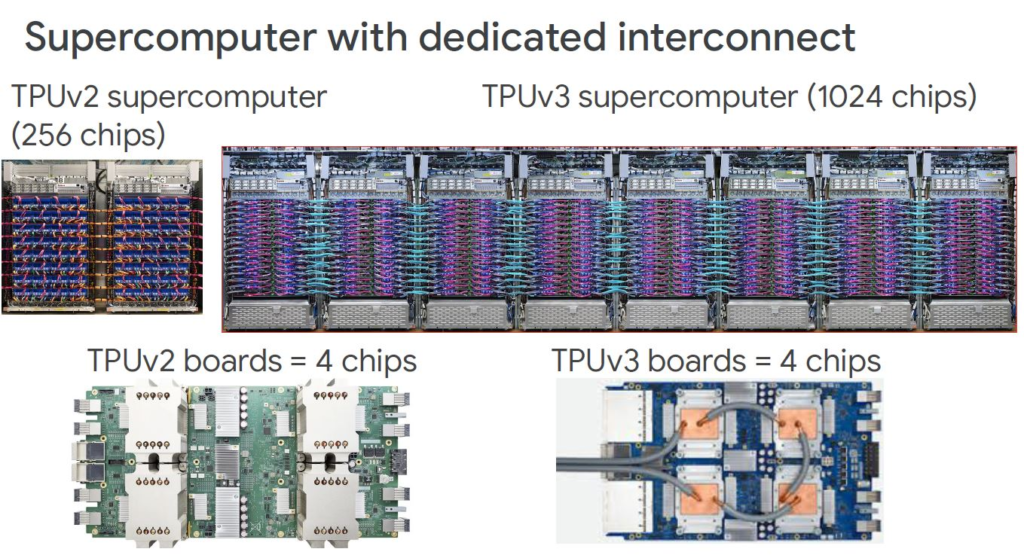
还有其他一些变化,但是,在系统级别,我们的加速器芯片数是前者的4倍,而petaflops是9-10倍,内存是8倍。我们还可以看到这些节点左侧的线缆连接器发生了很大的变化。
在Hot Chips 32上,Google更多地讨论了软件的扩展,这直接让Google成功发布了MLPerf 0.7的培训结果。Google在内部的产品上使用了这种硬件(或者也许他们还没有谈论的新一代)。

小结
其实TPU v3早在2018年就发布了,Google在2020年的Hot Chip 32上才有了一些细节的讨论,这并不奇怪,Google在硬件设计方面确实不透明,例如Google很少公开其关于ARM CPU的使用情况。相比之下,Fackbook和Microsoft的信息更加开放,AWS处于中间位置。其实以Google目前的体量,它是很难被模仿的。希望Google让其工程师更多地展示他们的工程能力。





