数据的激增正在推动对高端系统中更多和更快内存的新IC封装的需求。
但内存、封装和其他方面仍有许多挑战。例如,在系统中,数据在处理器和DRAM之间来回移动,DRAM是大多数芯片的主存储器。但有时这种交换会导致延迟和功耗,有时被称为内存墙。
为了解决服务器等高端系统中的这些问题,oem可以使用更快的dram。另一种解决方案是将逻辑和内存堆栈并集成到一个高级封装中。其想法是将逻辑和内存更紧密地结合在一起,以加快进程并打破内存墙。
在高端市场,有几种封装选择可供选择。在许多情况下,这些封装可能包含一个逻辑芯片以及一种称为高带宽内存(HBM)的技术。HBM是一种类似于一个小立方体的3D设备,它将DRAM芯片堆叠在一起,以提高系统中的内存带宽。到目前为止,HBM已经在高端系统中占据了一席之地,尽管在游戏、机器学习和其他应用等数据密集型工作负载的推动下,这项技术正在获得动力。
“HBM提供了更高的带宽和更好的功率效率,”TechSearch International总裁Jan Vardaman说。据称,与其他用于人工智能加速器的内存选项相比,HBM提供了更好的每比特皮焦耳。”
HBM已经在市场上销售了一段时间,它正在向新的更快的规范发展。尽管如此,HBM以及各种封装类型仍将是昂贵的。在制造业面临诸多挑战的情况下,降低成本仍将是困难的。HBM没有用于个人电脑和智能手机,因为它体积大,价格昂贵。
然而,今天的HBM可能远远不能满足未来的带宽需求。因此,供应商正在开发新技术。其中包括:
- 供应商正在对基于HBM2E规范的新版本HBM进行采样。下一个版本HBM3正在研发阶段。
- HBM通常出现在称为2.5D的高端封装类型中,但也有其他封装选项,包括扇形输出和桥接。
- 在研发方面,业界正在使用一种新的粘合工艺开发先进的hbm。厂商也在开发新的3D DRAM技术,即3DS(三晶片堆叠)DRAM。
更多的数据
网络中的数据量呈爆炸式增长。据思科称,到2022年,全球互联网协议(IP)流量或互联网上的数据流预计将达到每年4.8 ZB,高于2017年的每年1.5ZB。ZB等于1万亿千兆字节。
数据由个人电脑、智能手机和其他系统产生,然后由数据中心的服务器传输和处理。许多组织都有自己的数据中心。此外,亚马逊、谷歌、微软等运营的hyperscale数据中心是提供第三方云服务的大型设施。
据IDC称,超大规模数据中心的设施至少有10,000平方英尺,至少有5,000台服务器。据思科称,超大规模数据中心的总数将从2016年的338个增长到2021年的628个。思科表示,到2021年,这些中心将占IP流量的55%,高于目前的39%。
流量的激增刺激了对更快、内存更大的服务器的需求,但有一个问题。英特尔高级产品营销经理Manish Deo在最近的一份白皮书中表示:“内存带宽是下一代平台的关键瓶颈。”
简单地说,DRAM无法满足系统的带宽需求。但DRAM厂商正在采取措施,通过采用新的数据传输规范来解决这些问题。
dram采用DDR4接口标准。双数据速率DDR (double data-rate)技术,每个时钟周期传输两次数据。DDR4的运行速度高达3200 mbps。现在,DRAM厂商正在加紧生产基于新DDR5标准的设备。DDR5最高支持6400mbps。
还有其他变化。业界正在寻找将存储和处理功能更紧密地结合在一起的方法。
多年来,原始设备制造商通常将单独的组件,如处理器和内存,放在系统的主板上。但对于服务器来说,在主板上放置分立芯片会占用太多空间,而且在将数据从一个设备传输到另一个设备时效率低下。
据应用材料公司(Applied Materials)称,大约90%的内存能耗用于传输数据。应用材料公司半导体产品部主管Sean SK Kang在最近的一篇博客中说:“让内存更接近计算可以缓解这种情况。”“为了提高内存和计算的功耗和性能效率,我们正在研究多种策略,包括针对边缘和存储应用进行优化的内存、新的片上系统(SoC)封装方案、使用tsv的3D封装,以及有可能将能耗降低8倍的内存计算。”
这里有几个选项。一种选择是在同一个封装中集成多个晶片。“由于存储器是垂直堆叠的,3D存储器解决方案以更小的外形提供了最大的容量,”英特尔的Deo说。
HBM封装选项
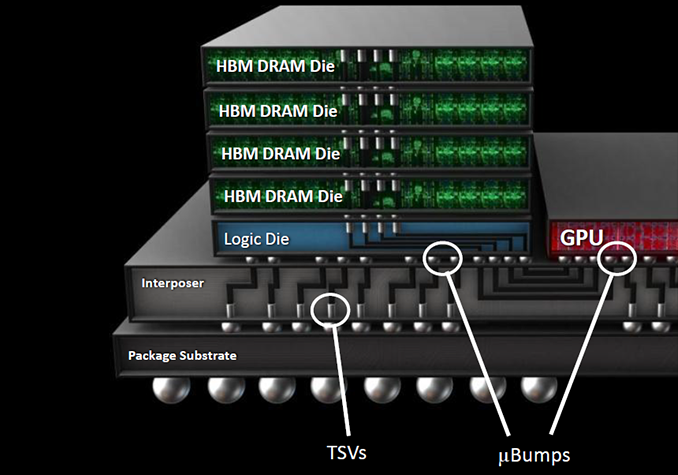
传统上,在高端系统中,封装公司将逻辑芯片和HBM集成在2.5D封装中。asic, fpga或gpu可用于逻辑芯片。三星和SK海力士是HBM的主要供应商,其他公司也在关注市场。几个不同的封装公司将HBM纳入一个封装。
在2.5D中,逻辑和HBM并排放置在集成了硅通孔(tsv)的中介器顶部。中间层充当芯片和电路板之间的桥梁。这反过来又使逻辑更靠近内存,从而实现更多带宽。
但2.5D也是一个昂贵的解决方案。封装尺寸很大,并且带来了热管理方面的挑战。这就是为什么2.5D被限制在高端应用。
降低成本是很困难的。2.5D是一个稳定的市场,但产量相对较小,不足以抵消复杂的制造过程。
HBM也有许多相同的问题。最初于2013年宣布,首批hbm是容量为1GB的4晶片堆叠DRAM产品。HBM有1,024个I/O,其中每个I/O或引脚的速度为1Gbps。这相当于128GB/s的带宽。I/ o是中间结构或pad。它们将来自芯片的信号连接到封装的引脚上。
今天的HBM产品基于HBM2规格,支持4/8GB容量。它具有相同的I/ o数(1024),但引脚速度为2.4Gbps,相当于307GB/s的带宽。
三年前,HBM的价格约为120美元/GB。根据TechInsights的数据,目前HBM2 (16GB, 4堆栈DRAM芯片)的单价约为120美元。这还不包括套餐的费用。
最新的HBM版本基于HBM2E规格,具有8/16GB容量。它有1,024个I/O,传输速率为3.2Gbps。“这意味着你可以获得更多的带宽,”TechInsights的分析师 Jeongdong Choe说。
在带宽为410GB/s的情况下,HBM2E是采样。Choe表示:“HBM2E时代将在2020年上半年到来。”
下一个版本,HBM3,具有4Gbps的传输速率和512GB/s的带宽。Choe 表示:“在HBM3之后,还没有具体的路线图。”
在所有情况下,HBM都将DRAM芯片堆叠在一起,并将它们与tsv连接。例如,三星的HBM2技术由8个8gb DRAM芯片组成,这些芯片使用5000个tsv堆叠和连接。总的来说,HBM2支持307GB/s的数据带宽,而4个DDR4 dimm支持85.2GB/s。
最近,三星推出了将12个DRAM芯片堆叠在一起的新HBM版本,这些芯片使用6万个tsv连接。封装厚度类似于8晶片堆叠版本。三星负责销售和营销的高级副总裁吉姆·埃利奥特(Jim Elliott)表示:“这是针对人工智能和高性能计算等数据密集型应用的。”“这给了我们24gb的密度。这比上一代产品提高了3倍。”
HBM2E和最终的HBM3更快。但是在每一次迭代中,2.5D/HBM包的制作变得更加困难。
在制造流程中,逻辑芯片和DRAM芯片分别在晶圆厂制造。然后,在HBM流程中,使用蚀刻工艺在每个DRAM芯片中形成微小的tsv,然后填充铜。CD均匀性在这里至关重要。
然后,在模具顶部形成微小的铜微凸点。凸点是基于焊料的互连结构,它在不同的模具之间提供小而快速的电气连接。在HBM中,凸起直径为25µm,间距为55µm。
凸起是通过一系列沉积、光刻和其他步骤在tsv上形成的。“由于需要堆叠DRAM芯片,因此需要TSV技术,从光刻角度来看,这将涉及提高分辨率和更紧密的覆盖。更大的挑战是由于堆积造成的模间差异,这可能会影响良率。这对光刻来说不是问题,但对其他工艺来说是问题,”Veeco技术营销高级总监Shankar Muthukrishnan说。
事实上,细音高结构有几个挑战。EV集团业务发展总监Thomas Uhrmann表示:“随着芯片到芯片互连带宽的提高,互连间距和焊料体积必须缩小。”“由于这些原因,在芯片组装过程中控制焊料等液化系统更具挑战性,其中由于焊料不受控制的挤压而导致触点之间的短路是最常见的故障机制。”
与此同时,一旦凸起形成,骰子被翻转并放置在一个临时载体上。结构的背面变薄,暴露出tsv。然后,在背面,在模具上形成微凸起。临时的载体是脱粘的,导致每一面都有凸起的骰子。应力是粘合/脱粘过程中的一个问题。
最后,将DRAM晶片彼此连接并粘合,并且在每个晶片之间插入下填充材料。
对于细间距要求,行业使用热压缩粘合(TCB),这是一个缓慢的过程。
先进的hbm
与此同时,在研发方面,业界正在研究新技术,以克服当今软件包的限制。
例如,在2.5D中,最先进的微凸块是间距为40μm的微小结构。40μm的间距相当于25μm的凸起直径,间距为15μm。
展望未来,业界可以将凹凸间距缩小到20μm,甚至10μm。然后,凸块和柱子的纵横比变得难以控制。
因此,从20μm到10μm的凹凸节距开始,行业需要一种新的互连解决方案,即铜混合键合。为此,我们的想法是使用铜对铜扩散连接技术直接堆叠和连接模具,从而消除对凸起和支柱的需要。
这使得新的2.5D封装、3d – ic和HBMs成为可能。这些可能会在2021年或更早的时候出现。3D-IC是一种模拟传统SoC (system-on-a-chip)的系统级设计。与将所有功能集成在一个模具上的soc不同,3D-ICs将更小的模具集成在一个包中。3d – ic可能具有更低的成本和更好的收益率。
铜杂化键并不是什么新鲜事。多年来,该技术一直用于CMOS图像传感器。但是,迁移先进芯片堆叠技术,如存储在内存和存储在逻辑上,是具有挑战性的,涉及复杂的晶圆厂级过程。
K&S公司的Chylak说:“人们正试图用这种工艺设计芯片与晶圆的键合。”“这很有挑战性,因为它需要一个带组装机的一级洁净室迷你环境。该机器需要在3 σ时达到0.2μm的高精度。这将是一台昂贵的机器。”
尽管如此,台积电等公司仍在开发铜键合技术。其他公司正在从Xperi公司获得这项技术的授权,该技术被称为Direct Bond Interconnect (DBI)。DBI使节距降低到1μm。
一些图像传感器供应商已经获得了DBI的许可。UMC和其他公司也获得了许可。“我们相信晶圆键合是未来主要的技术趋势之一,”UMC企业营销副总裁Steven Liu说。
混合键合可以用来将两个晶圆片连接在一起(晶圆对晶圆键合)和一个晶圆对一个晶圆(芯片对晶圆键合)。
在流动过程中,金属垫在晶圆片上凹进去。表面被平面化,接着是等离子体激活步骤。用一个单独的晶圆重复这个过程。晶圆采用介电-介电键连接,然后是金属-金属连接。
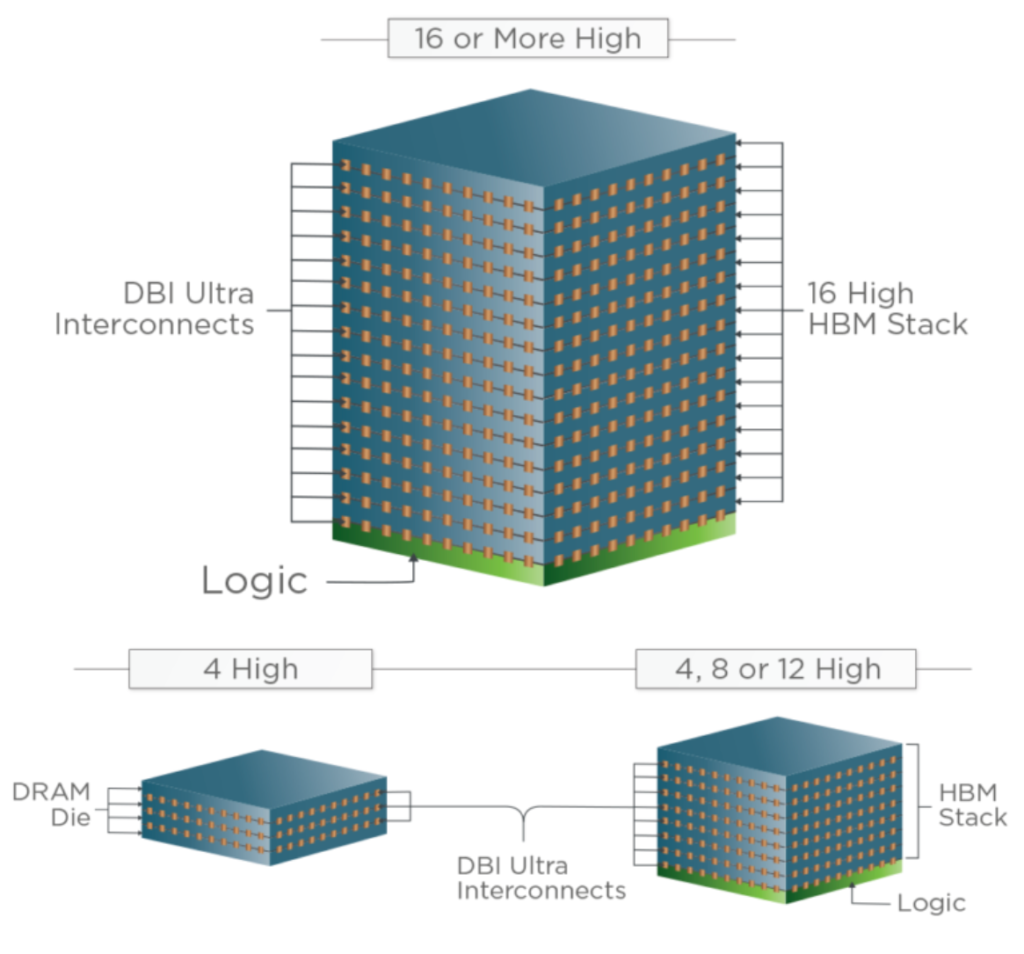
在研发方面,厂商正在使用混合键合技术研发新型HBM,例如低外形的16模栈。有些人正致力于堆叠三个DRAM die,即3DS。台积电演示了一个四DRAM芯片栈。
使用Xperi的技术,每个骰子之间没有欠填充。“今天,他们堆叠高性能DRAM的方式是使用倒装芯片或热压缩键合。他们面临的问题是: 1)缩放到更精细的音高; 2)它正在处理不足填埋的问题,”Xperi旗下Invensas的总裁Craig Mitchell说。“当你用欠填充填充时,它的导热性不高。最后发生的是栈底的骰子和栈顶的骰子的温度不同于中间的。”
消除欠填充可以实现低剖面堆叠。“堆栈的行为更像是一个die。我们在堆栈中获得了更均匀的热量,”米切尔说。
如上所述,尽管如此,铜杂化键合对于先进的封装来说是一个具有挑战性的过程。“晶圆对晶圆级键合有两个致命缺陷,”K&S公司的Chylak说。“芯片需要相同的大小。在大多数应用中,情况并非如此,因此你失去了宝贵的硅空间。”
此外,晶圆产量并不总是完美的。假设两种晶圆的收率都是80%。Chylak说:“最终的包将产生64%的收益。”“你最终会把一些好的die与坏的die结合起来。”
结论
显然,HBM有几种封装选择。当然,HBM并不适用于所有应用程序。你不会在智能手机上看到它,也不会取代DRAM。
但是HBM在高性能应用中越来越重要。问题是,在数据需求激增的情况下,它能否跟上。