背景
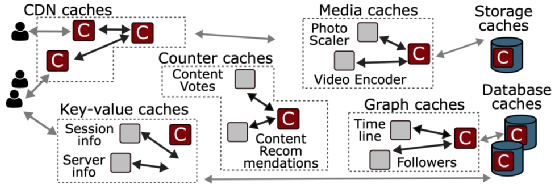
网络服务几乎在系统架构的每一层都依赖于缓存。大型网络服务依靠缓存系统来实现高性能和高效率。例如,在Facebook,CDN缓存为70%的网络请求提供服务,将延迟降低了一个或多个数量级。一台缓存服务器可以取代几十台后端数据库服务器,实现20倍的吞吐量和超过80%的命中率。通常,每个缓存都是由一个不同的团队独立实现和维护的,并且对其功能高度专业化。在Facebook,各种各样的缓存系统构成了系统架构的一个组成部分。Facebook的架构包括CDN缓存、键值应用缓存、社交图谱缓存和媒体缓存(图1)。缓存在亚马逊、Twitter、Reddit以及其他许多大型网络服务中扮演着类似的角色。然而,每个团队独立实现和维护的缓存系统存在重复的逻辑和功能,忽略了不同缓存系统共同面临的困难挑战,大大增加了部署、维护和扩展每个缓存所需的整体努力。
问题
1. 多种缓存系统的冗余
Facebook的每个缓存系统都是单独实现的。例如,如图1所示,Facebook分别设计了CDN缓存、键值缓存、社交图谱缓存、存储缓存、数据库缓存,以及其他许多缓存。这些高度专业化的系统都需要一个高度专业化的缓存,以实现复杂的一致性协议,利用自定义的数据结构,并针对所需的硬件平台进行优化。尽管这些缓存系统服务于不同的工作负载,需要不同的功能,但它们在设计和部署方面有许多共同的挑战。所有这些系统每秒都要处理数以百万计的查询,缓存工作集大到需要同时使用闪存和DRAM进行缓存,并且必须容忍因应用程序更新而频繁重启,这在Facebook的生产环境中很常见。随着Facebook的缓存系统数量的增加,为每个系统维持独立的缓存实现变得难以维持。通过重复解决相同的工程难题,团队重复了彼此的努力,产生了多余的代码。此外,维护独立的缓存系统也阻碍了系统之间分享性能优化带来的效率提升。
2. DRAM开销
随着传统的动态随机存取存储器 (DRAM) 缓存变得更加昂贵并且需要更多的能力来扩展。在大型服务器的场景下,全部采用DRAM作为缓存介质是不现实的,这将会造成巨大的成本开销。像 Facebook 这样的公司正在探索硬件选择,例如非易失性存储器 (NVM) 驱动器来增强他们的缓存系统。这种 DRAM 和 NVM 混合模型向前迈进了一步,但需要创新的缓存设计来利用混合缓存的全部潜力。
探索
1. 缓存数据集分布(冷热)
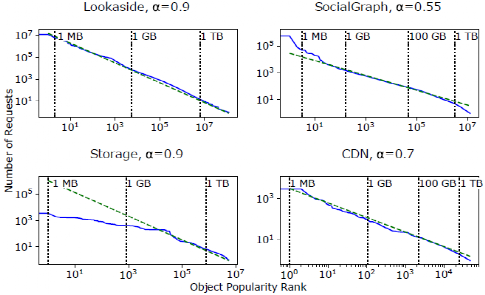
工作负载的流行度分布衡量的是每个键在某个时间范围内的取样跟踪的频率。这些频率表明系统中不同对象的相对受欢迎程度。之前对CDN和网络工作负载的测量表明,高度倾斜的Zipf分布是一种常见的流行分布。在Zipf分布中,”最受欢迎的20%的对象占了80%的请求”。图2显示了Facebook四个工作负载的对数尺度的流行分布。在这个尺度上,Zipf分布将是一条具有负斜率(-α)的直线。Lookaside是四个系统中唯一一个流行度分布为Zipfian的系统,α接近于1。Storage的分布在分布的头部更平坦,尽管尾部遵循Zipf分布。此外,尽管是Zip-fian分布,SocialGraph和CDN的分布分别表现为α=0.55和α=0.7。较低的α意味着明显较高比例的请求进入流行分布的尾部,这导致了更大的工作集。
2. 缓存数据集分布流失(冷热变化)
流失指的是由于新keys的引入和现有keys的流行程度随着时间的推移而产生的工作集的变化。流行的YCSB工作负载生成器假设没有流失,即每个密钥在整个基准期间保持同样的流行。这个基准和无流失假设被广泛用于系统论文的评估中。
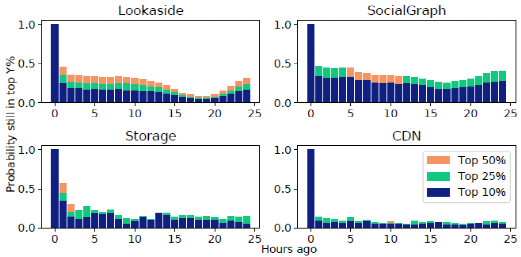
在Facebook的生产工作负载中体现出有很高程度的流失率。如果一个对象属于收到最多请求的10%的对象,我们就定义它是受欢迎的。图3显示了流行对象的集合如何随时间变化。例如,x=3处的蓝条显示了一个3小时前很受欢迎的对象仍然在前10%最多请求的对象中的概率。在所有的工作负载中,超过三分之二的热门对象在一小时后就跌出了前10%的位置。这种高流失率与使用哪个小时作为基线、不同的百分比(例如前25%)以及不同的时间粒度(例如,10分钟后,50%的热门对象不再受欢迎)无关。这种高流失率增加了时间定位的重要性,使缓存策略更难根据过去的访问模式来估计对象的受欢迎程度。
3. 缓存对象的粒度变化
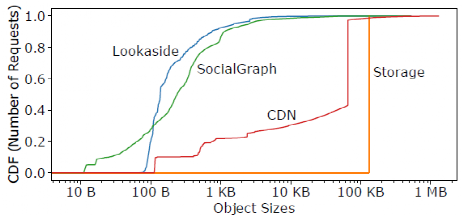
除了受欢迎程度和流失率之外,对象的大小在缓存性能上也起着关键作用。图4显示了四个大型用例的对象大小分布。对于Storage和CDN,64KB和128KB的小块非常常见,这是将大对象分成小块的结果。对于Lookaside和SocialGraph,对象的大小跨越了七个数量级。
4.急促访问
Facebook的工作负载流量是相当突发性的。图5显示了与泊松到达序列相比的实际请求到达率,这通常是在系统评估中假设的。图5显示,实际到达率的变化比Poisson暗示的要大得多。这对CDN来说尤其明显,它在相当稳定的请求率之上有急剧的流量爆发。多变的到达率使得缓存系统很难有足够的资源来维持负载高峰期的低延迟。
方法和设计
1. 混合式缓存架构
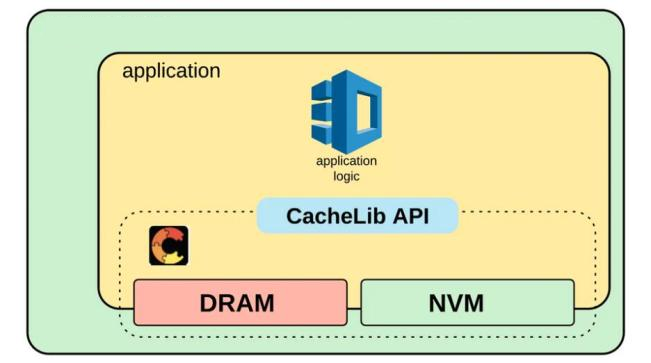
相对来说这些东西需要写很多相同的缓存逻辑:换出策略,内存使用,处理 empty cache 等,所以 Facebook 造了一套通用的 CacheLib,用来节省团队造轮子的功夫。同时,很重要的一点是对于 Flash 的使用。用 SSD/Flash 当缓存,相对来说能够提供较低的成本,和可以接受的性能。相对 DRAM,机器一般会提供更大的盘,同时,SSD 也会提供更低的成本和更可接受的性能。这套功能在 CacheLib 中叫做 HybridCache,CacheLib 允许指定存储设备。CacheLib 对外提供的是 byte-addressable 的对象和 cache。它提供了一套线程安全的 api,来处理对应的逻辑:

此外,CacheLib 还给自定义的 Serialize/Deserialize 定义了接口,以便用户塞一些自定义结构体。
2.小对象缓存优化 (Small Object Cache)
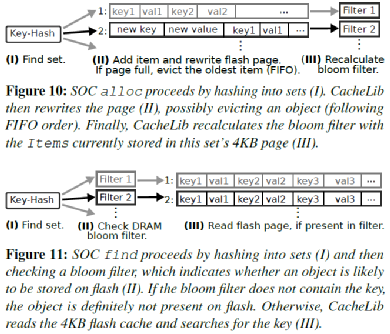
SOC存储很多小对象,如果像LOC一样存储它们的索引,系统整个DRAM开销会非常大。所以SOC使用了一个近似的索引来实现对应的逻辑。如图7所示,SOC 把小对象划分成很多 sets,每个包含一个4kB page,按照FIFO存储对象。每组有一个8 bytes的Bloom Filter。这里把key查一下Bloom Filter,如果不存在则返回不存在,否则读取整个Page并顺序扫描。
3. 大对象缓存优化 (Large Object Cache)
LOC 存储的都是 2kB 以上的对象。作者认为,这些大对象让用户能够在内存中放置这些对象的 Index。具体的对象按照 4kb 的大小对齐。论文用了 4 bytes 的大小定位这部分的数据:4 bytes最大能表示232个数据,可以放 16T的数据了。
LOC 的内存索引存储,LOC 会主动把 SSD 划分成不同的区域,根据这个来判断大小。然后LOC对象的地址会对齐4kB,这大概是一个SSD Page的大小,这样能够保证一个 SSD Page 不会存储过多的对象;同时地址对齐 4kB,减小地址对象的开销。如果对象很大,那么它会连续跨多个页,需要把他们都读起来。如果一个cache read读取有一个相同的hash key,这里会把Flash中的元数据读起来。这里在元数据上需要存储对应的key。然后把这个key跟用户请求的真实 key 比较,判断具体是否命中缓存。
这里还有一个 Erase 相关的优化。LOC 的 Erase 是以 Block 为单位的,它默认 16MB,但是是可配置的。这实际上相当于 抹去 SSD 的 Block,通过这种方式来增加写的顺序写。如果淘汰出的对象是一个比较热的对象,可能会重新加入 cache 中。
实验结果
实验性能对比包含三个方面,分别为缓存命中率、吞吐量和暖启动。
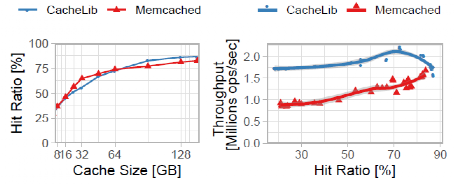
缓存命中率和吞吐量性能:图12显示了8到144GB的缓存规模和1亿个对象的典型工作集的命中率和吞吐量。Memcached和CacheLib实现了相似的命中率,Memcached在小的缓存大小时略高,在大的缓存大小时略低。在所有的缓存大小中,CacheLib实现了比Memcached更高的吞吐量,每秒钟处理的请求比Memcached多60%。
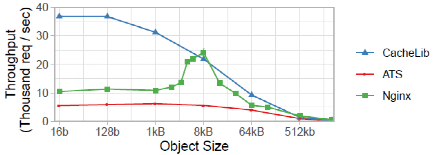
小对象缓存性能:图9显示,CacheLib对小对象的明确处理为Flash缓存提供了比NGINX和ATS更大的优势。当对象的大小变大时,这种优势就会减弱。最终,对象的大小变得足够大,以至于这三个系统都变成了网络约束,其吞吐量急剧下降。
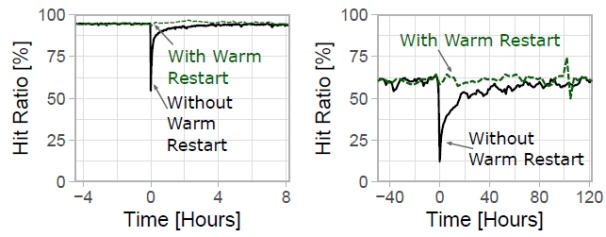
暖启动:图10显示了L1和L2 SocialGraph缓存重启时的命中率,而没有执行暖重启。在没有启用这个功能的情况下,缓存重启会导致命中率下降,然后慢慢恢复正常。这在二级混合缓存中尤其具有破坏性,因为大容量的缓存可能需要几天时间来 “热身”。这样的命中率下降可以转化为后端系统的暂时过载,因为后端系统假定有相对稳定的到达率。
总结
Cachelib的出现避免了缓存系统重复造轮子的现象,降低了系统的冗余程度和开发维护成本。同时cachelib设计了混合式缓存架构,使用性价比高的SSD进行混合式缓存,使得缓存系统的成本降低同时提升性能。与传统的内存作为缓存层相比,cachelib考虑到闪存的特性,进行了小对象缓存优化,并且在性能上有很大改进。
感谢本次论文解读者,来自华东师范大学的博士生宋云鹏,主要研究方向为软硬件协同设计。