

AI这个话题从2016年开始大热,至今已有五年多的时间了。虽然现在各类新闻媒体上对AI技术的报道似乎减少了一些,但其实这是符合技术发展规律的。在经过了最初的概念爆炒阶段后,AI技术正在进入技术落地的实用阶段。作为支撑AI技术的硬件基础,GPU服务器显然是任何一个从事AI技术开发的厂家所必需的硬件设备。虽然如今的GPU服务器领域仍然是NVIDIA一家独大的局面,但Intel、AMD、Xilinx,以及各种初创企业都在奋力追赶之中。在五花八门的GPU和AI加速芯片产品背后,GPU服务器硬件设备究竟在沿着什么样的技术路线发展?本文抛砖引玉,谈谈对这一问题的看法。
熟悉GPU服务器和NVIDIA产品的人都知道,除了标准的PCIe形态GPU卡之外,要想获得更高的GPU计算性能,就需要使用NVIDIA SXM形态的GPU模块。NVIDIA SXM GPU模块虽然性能更强,但却需要使用NVIDIA私有的NVLink接口进行互联,而这一接口的使用需要通过付费的方式才能获得NVIDIA的授权,这自然就增加了GPU服务器的使用成本。

正是看到了NVIDIA NVLink对普及GPU服务器所带来的影响,OCP组织才成立了OAI/OAM项目组。通过OAM子项目,定义了业界通用的扣卡形态的GPU/AI加速模块。OAM模块对外提供标准的信号接口,芯片厂家只要将其GPU/AI加速芯片做成OAM模块的形态,就可以在任何支持OAM模块的服务器上使用。这样一来,服务器系统厂家和用户都有望摆脱对NVIDIA的独家依赖。通过市场竞争的方式,获得成本更低的GPU/AI加速模块。不同厂家的OAM模块可以彼此替换,因此也就不存在类似于NVLink这样的对外私有协议接口了。
在2019年的OCP Summit大会上一经推出,OAM模块就受到了业界的追捧。不论是Intel、AMD、Xilinx这样的芯片大厂,还是寒武纪、Habana、燧源这样的初创企业,都走上了OCP OAM的道路。可以说,这是GPU服务器在接下来的几年里最重要的技术发展方向之一。
有了OAM模块,下一步就要考虑用什么样的方式将其连接起来。NVIDIA的NVLink链路及其拓扑的发展变化给业界提供了很好的范例。从每个P100 GPU出4组NVLink链路进行彼此互联,到现如今在A100 GPU上通过12组NVLink链路、外加NVSwitch进行所有GPU模块之间的全互联,GPU和GPU之间不仅完全实现了点对点的直接访问,还拥有了高达600GB/s的数据传输带宽。对AI应用而言,数据传输带宽越大,GPU的硬件性能就越能够充分地发挥出来。
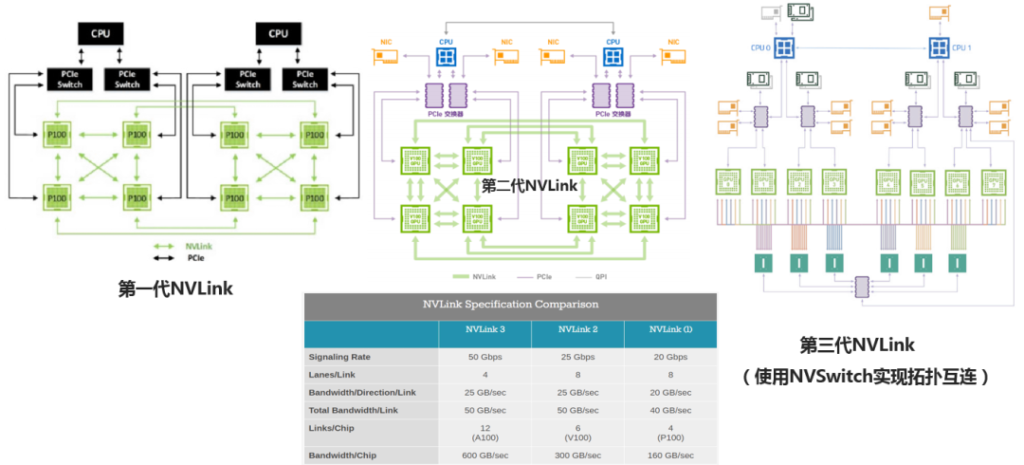
于是在OCP OAI项目里,很自然地也定义了全互联的OAM模块联接拓扑。由于OAM模块对外出的接口具有高度的灵活性,因此在OAM模块全互联拓扑之外,还可以使用多种互联拓扑变种。当然,最重要的一点是,OAM模块的互连拓扑不存在额外收费的问题,而且所有厂家的OAM模块均支持OCP OAI规范中定义的拓扑形式。对于OAM模块的全互联拓扑,需要服务器系统厂家通过开发OAM通用基板的方式来支持,这将是对GPU服务器系统设计提出来的第二个新的要求。
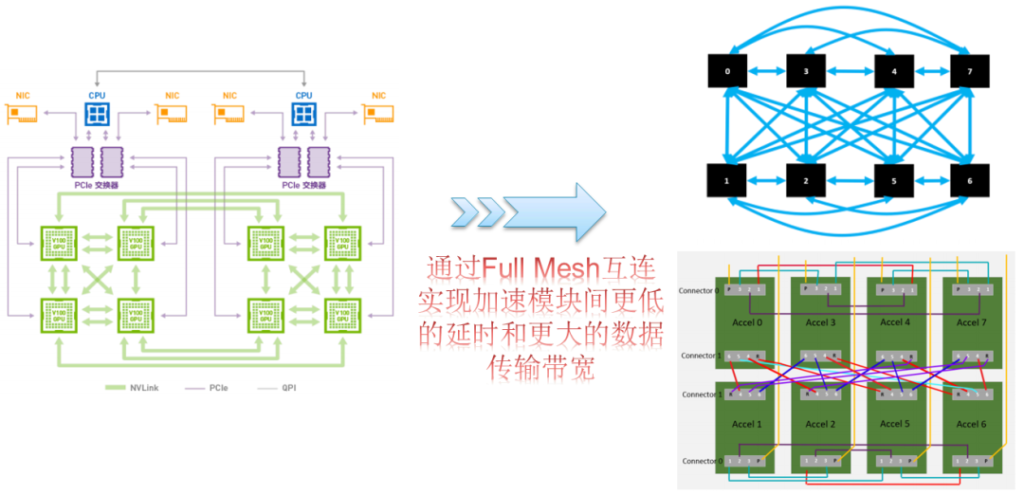
更大的AI模型和训练数据集要求更大的数据传输带宽,而更大的数据传输带宽将会把更多需要计算处理的数据传递给GPU/AI加速模块。既然数据更多了,那么就需要更大的片上内存来存放这些数据。通过在片上一次性存储更多的数据,可以有效地减少数据在GPU内存和硬盘之间来回搬移的能量消耗,从而提高每焦耳能量的计算效能。于是我们看到从P100到V100再到最新的A100 SXM GPU模块上,NVIDIA在功耗和面积允许的条件下不停地增加HBM内存容量。

NVIDIA GPU上的片上内存从HBM2升级到HBM2E、容量从16GB一路提升到目前的80GB。其它厂家的GPU和AI加速芯片也都沿用了同样的设计策略,毕竟HBM是目前能够做到的片上最大内存容量和带宽。随着HBM3内存的逐渐成熟,相信它将会出现在下一代GPU/AI加速模块上,从而满足更大规模AI模型训练和推理的需求。
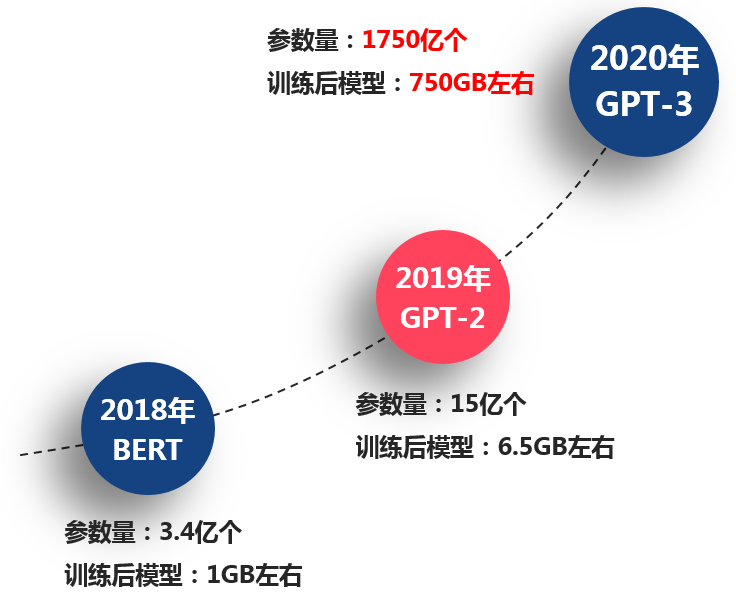
在2020年的时候,一个被命名为GPT-3的AI模型横空出世,向人们展示了其极强的文本处理能力。一篇文章只要给它一个开头,这个模型就能够帮你完成文章剩下的所有内容,而且写作手法能够一脉相承。为了达到这样的智能程度,GPT-3模型的参数量达到了创纪录的1750亿个,训练后的模型体积则有750GB左右。而到了今年,Google推出了混合专家(Mix of Expert)AI模型系统,其1.6万亿的参数量瞬间秒杀了GPT-3模型。未来AI模型会发展到什么程度,这还真是一个很难回答的问题。
既然AI模型已经变得如此庞大,那么只有把GPU服务器级联起来,构成GPU Pod,才能有足够的资源在可接受的时间范围内完成AI模型训练。使用以太网或Infiniband网络是业界常用的GPU服务器级联方式,这就要求在GPU服务器里配置高带宽的网卡。
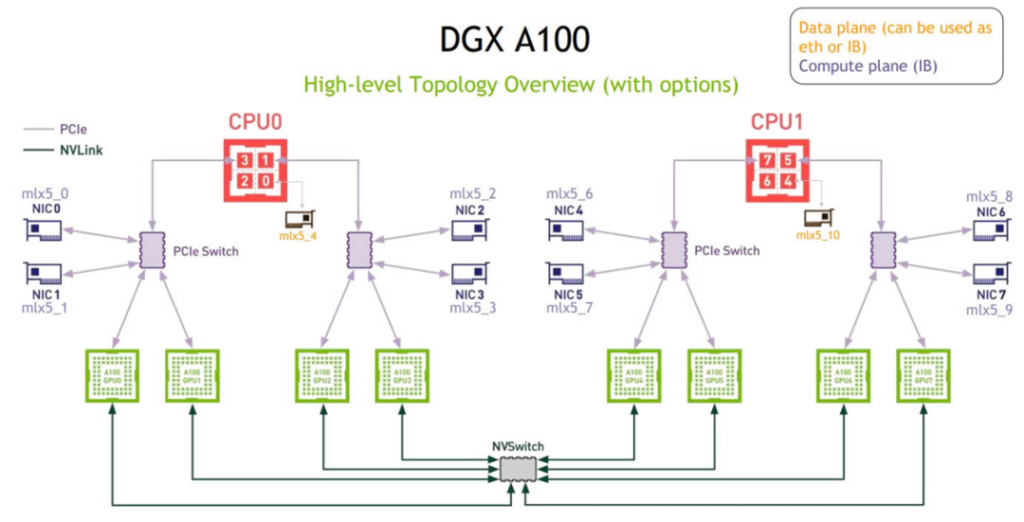
NVIDIA在最新的DGX A100 GPU服务器里总共配置了10块高速网卡,其中的8块网卡分别配置给了8个A100 GPU模块,剩下的2块网卡则分别配置给了2个CPU芯片。为什么要给GPU配置这么多的网卡呢?这是因为NVIDIA GPU在服务器内部会通过聚合通信的方式形成通信环。每台GPU服务器上的通信环通过网卡与外部设备进行通信,从而构成GPU Pod里一个更为庞大的通信环。
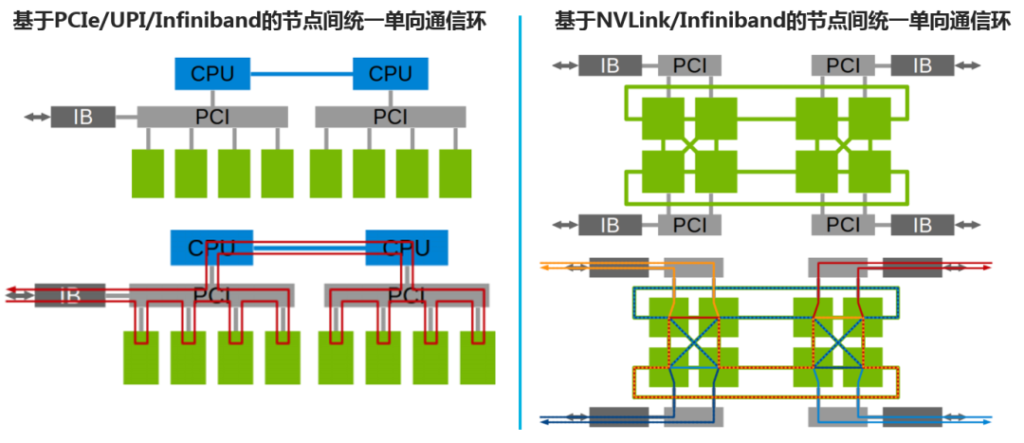
通过为每块GPU分配一块高速网卡,可以确保每块GPU上的数据在通信环里传输时不会有带宽瓶颈。这样一来,整个GPU Pod就可以实现高效的数据处理和交互能力。
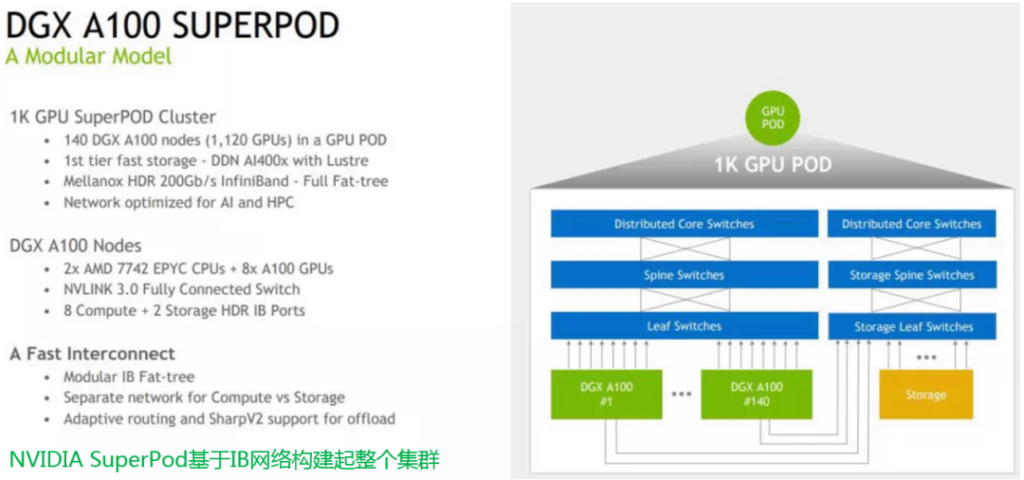
NVIDIA用DGX A100 GPU服务器构建了命名为Selene的AI计算集群,这一AI计算集群的性能之强,已经在Top500超算榜单上位列第六名了。即使不需要这么大的计算集群,在进行少数几台GPU服务器级联的时候,如果每台GPU服务器上都能够配备多块高速网卡,同样能够增强GPU级联系统里数据通信环的带宽,从而带来更高的级联系统AI计算性能。这一发展趋势自然就要求GPU服务器里能够有更多的扩展槽位来支持高速网卡了。
总 结
使用OCP OAM模块来打破NVIDIA一家独大的局面,通过GPU/AI加速模块间的全互联取得GPU服务器内部更大的数据传输带宽,在单个GPU上放置更大容量的HBM内存,以及通过在GPU服务器内部配置更多网卡来实现更好的GPU服务器级联扩展,这些可以说是GPU服务器在接下来的3-5年内大概率的技术发展方向。
不过也要看到,AI是一个新技术不断涌现的领域。Cerebras这家初创公司推出了Wafer级芯片,用一整个晶圆来提供用户需要的计算能力和数据存储空间,基于Wafer级芯片的Cerebras CS-1/2系统可以看成是一个大号的GPU服务器。NVIDIA更是在推动自己熟悉的GPU向前发展的同时,开始进入CPU领域,开发代号为Grace的ARM CPU。ARM CPU和GPU的融合,将使得NVIDIA有可能抛开x86体系,从而进一步改变未来AI计算的形式。